OLAP technology. Coursework: OLAP technology In what year did the first olap systems appear?
OLAP(from the English OnLine Analytical Processing - operational analytical data processing, also: analytical data processing in real time, interactive analytical data processing) - an approach to analytical data processing based on their multidimensional hierarchical representation, which is part of the broader field of information technology - business -analysts ().
For a catalog of OLAP solutions and projects, see the OLAP section on TAdviser.
From the user's point of view, OLAP-systems provide tools for flexible viewing of information in various sections, automatic receipt of aggregated data, performing analytical operations of convolution, detailing, and comparison over time. All this makes OLAP systems a solution with obvious advantages in the field of data preparation for all types of business reporting, involving the presentation of data in various sections and different levels of hierarchy - for example, sales reports, various forms of budgets, and so on. The advantages of such a representation in other forms of data analysis, including forecasting, are obvious.
Requirements for OLAP systems. FASMI
The key requirement for OLAP systems is speed, which allows them to be used in the process of an analyst’s interactive work with information. In this sense, OLAP systems are contrasted, firstly, with traditional RDBMS, samples from which with typical queries for analysts using grouping and aggregation of data are usually expensive in terms of waiting time and loading of the RDBMS, so interactive work with them for any significant volumes data is complex. Secondly, OLAP systems are also opposed to the usual flat-file presentation of data, for example, in the form of frequently used traditional spreadsheets, the presentation of multidimensional data in which is complex and not intuitive, and operations for changing the slice - points of view on the data - also require time and complicate interactive work with data.
At the same time, on the one hand, data requirements specific to OLAP systems usually imply data storage in special optimized typical tasks OLAP structures, on the other hand, directly extracting data from existing systems during the analysis process would lead to a significant drop in their performance.
Therefore, an important requirement is to ensure the most flexible import-export link between existing systems, acting as a data source and an OLAP system, as well as an OLAP system and external data analysis and reporting applications.
Moreover, such a combination must satisfy the obvious requirements of supporting import-export from several data sources, implementing procedures for cleaning and transforming data, unifying the used classifiers and reference books. In addition, these requirements are supplemented by the need to take into account various data update cycles in existing information systems and unify the required level of data detail. The complexity and versatility of this problem led to the emergence of the concept of data warehouses, and, in a narrow sense, to the identification of a separate class of data conversion and transformation utilities - ETL (Extract Transform Load).
Active Data Storage Models
We indicated above that OLAP assumes a multidimensional hierarchical representation of data, and, in a sense, is opposed to RDBMS-based systems.
This, however, does not mean that all OLAP systems use a multidimensional model to store active, “working” system data. Since the active data storage model influences all requirements dictated by the FASMI test, its importance is emphasized by the fact that it is on this basis that OLAP subtypes are traditionally distinguished - multidimensional (MOLAP), relational (ROLAP) and hybrid (HOLAP).
However, some experts, led by the aforementioned Nigel Pends, indicate that classification based on one criterion is not complete enough. Moreover, the vast majority of existing OLAP systems will be of the hybrid type. Therefore, we will dwell in more detail on active data storage models, mentioning which of them correspond to which of the traditional OLAP subtypes.
Storing active data in a multidimensional database
In this case, OLAP data is stored in multidimensional DBMSs that use designs optimized for this type of data. Typically, multidimensional DBMSs support all typical OLAP operations, including aggregation along the required hierarchy levels and so on.
This type of data storage, in a sense, can be called classic for OLAP. However, all steps for preliminary data preparation are fully necessary for it. Typically, multidimensional DBMS data is stored on disk, however, in some cases, to speed up data processing, such systems allow data to be stored in RAM. For the same purposes, storing pre-calculated aggregate values and other calculated values in the database is sometimes used.
Multidimensional DBMSs that fully support multi-user access with competing read and write transactions are quite rare; the usual mode for such DBMSs is single-user with write access with multi-user read access, or multi-user read-only.
Among the shortcomings characteristic of some implementations of multidimensional DBMSs and OLAP systems based on them, one can note their susceptibility to an unpredictable growth in the amount of space occupied by the database from a user point of view. This effect is caused by the desire to minimize the reaction time of the system, which dictates storing pre-calculated values of aggregate indicators and other quantities in the database, which causes a nonlinear increase in the volume of information stored in the database with the addition of new data values or measurements.
The extent to which this problem manifests itself, as well as the related problems of effectively storing sparse data cubes, is determined by the quality of the approaches and algorithms used for specific implementations of OLAP systems.
Storing active data in a relational database
OLAP data can also be stored in a traditional RDBMS. In most cases, this approach is used when trying to “painlessly” integrate OLAP with existing accounting systems or RDBMS-based data warehouses. At the same time, this approach requires the RDBMS to ensure effective fulfillment of the requirements of the FASMI test (in particular, ensuring minimum system response time) some additional features. Typically, OLAP data is stored in denormalized form, and some of the pre-calculated aggregates and values are stored in special tables. When stored in a normalized form, the effectiveness of RDBMS as a method for storing active data decreases.
The problem of choosing effective approaches and algorithms for storing precomputed data is also relevant for OLAP systems based on RDBMS, so manufacturers of such systems usually focus on the merits of the approaches used.
In general, it is believed that OLAP systems based on RDBMS are slower than systems based on multidimensional DBMSs, including due to data storage structures that are less efficient for OLAP tasks, but in practice this depends on the characteristics of a particular system.
Among the advantages of storing data in an RDBMS is the greater scalability of such systems.
Storing active data in flat files
This approach involves storing chunks of data in regular files. It is usually used as a complement to one of the two main approaches to speed up work by caching the latest data on disk or in random access memory client PC.
Hybrid approach to data storage
Most manufacturers of OLAP systems that promote their complex solutions, often including, in addition to the OLAP system itself, DBMS, ETL (Extract Transform Load) and reporting tools, currently use a hybrid approach to organizing the storage of active system data, distributing it in one way or another between RDBMS and specialized storage, as well as between disk structures and in-memory caching.
Since the effectiveness of such a solution depends on the specific approaches and algorithms used by the manufacturer to determine whether what data and where to store, then hastily draw conclusions about the initially greater efficiency of such solutions as a class without assessing the specific features of the system under consideration.
OLAP(eng. on-line analytical processing) – a set of methods for dynamic processing of multidimensional queries in analytical databases. Such data sources are usually quite large in volume, and one of the most important requirements in the tools used to process them is high speed. In relational databases, information is stored in separate tables that are well normalized. But complex multi-table queries are executed quite slowly in them. Significantly better performance in terms of processing speed in OLAP systems is achieved due to the peculiarities of the data storage structure. All information is clearly organized, and two types of data storage are used: measurements(contain directories divided into categories, for example, points of sale, clients, employees, services, etc.) and data(characterize the interaction of elements various measurements, for example, on March 3, 2010, seller A provided a service to customer B in store C for the amount of D monetary units). Measures are used to calculate results in the Analysis Cube. Measures are collections of facts aggregated by corresponding selected dimensions and their elements. Thanks to these features, complex queries With multidimensional data, much less time is spent than with relational sources.
One of the main vendors of OLAP systems is Microsoft Corporation. Let's look at the implementation of OLAP principles using practical examples of creating an analytical cube in the Microsoft SQL Server Business Intelligence Development Studio (BIDS) and Microsoft Office PerformancePoint Server Planning Business Modeler (PPS) applications and get acquainted with the possibilities of visually representing multidimensional data in the form of graphs, charts and tables.
For example, in BIDS it is necessary to create an OLAP cube using data about an insurance company, its employees, partners (clients) and points of sale. Let's assume that the company provides one type of service, so measurement of services will not be needed.
First let's define the measurements. The following entities (data categories) are associated with the company’s activities:
- Points of sale
- Employees
- Partners
Next, you need one table to store facts (fact table).
Information can be entered into tables manually, but the most common way is to load data using the Import Wizard from various sources.
The following figure shows the flow of manually creating and populating dimension and fact tables:
Fig.1. Tables of dimensions and facts in the analytical database. Creation sequence
After creating a multidimensional data source in BIDS, you can view its presentation (Data Source View). In our example, we will get the circuit shown in the figure below.
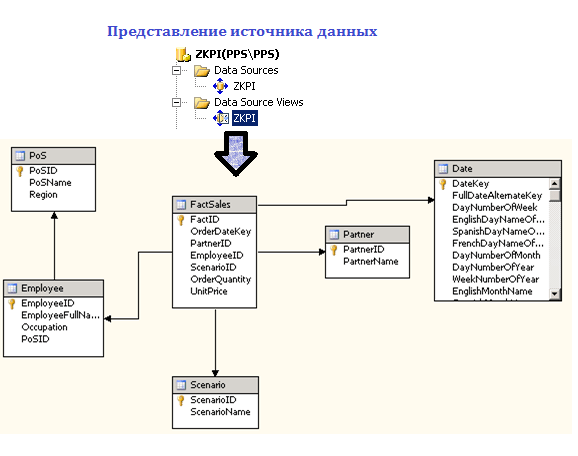
Fig.2. Data Source View in Business Intelligence Development Studio (BIDS)
As you can see, the fact table is connected to the dimension tables through a one-to-one correspondence of identifier fields (PartnerID, EmployeeID, etc.).
Let's look at the result. On the cube explorer tab, by dragging measures and dimensions into the totals, rows, columns and filters fields, we can get a view of the data of interest (for example, concluded transactions on insurance contracts concluded by a certain employee in 2005).
conductingA lot has been written about OLAP lately. We can say that there is some boom around these technologies. True, for us this boom was somewhat late, but this, of course, is connected with the general situation in the country.
Enterprise-scale information systems, as a rule, contain applications designed for complex multidimensional analysis of data, its dynamics, trends, etc. Such analysis is ultimately intended to support decision making. These systems are often called decision support systems.
Decision support systems usually have the means to provide the user with aggregate data for various samples from the original set in a form convenient for perception and analysis. As a rule, such aggregate functions form a multidimensional (and, therefore, non-relational) data set (often called a hypercube or metacube), the axes of which contain parameters, and the cells contain aggregate data dependent on them - and such data can also be stored in relational tables, but in this case we are talking about the logical organization of data, and not about the physical implementation of their storage). Along each axis, data can be organized into a hierarchy, representing different levels of detail. Thanks to this data model, users can formulate complex queries, generate reports, and obtain subsets of data.
The technology for complex multidimensional data analysis is called OLAP (On-Line Analytical Processing).
OLAP is a key component of data warehousing.
The concept of OLAP was described in 1993 by Edgar Codd, a renowned database researcher and author of the relational data model (seeE.F. Codd, S.B. Codd, and C.T. Salley, Providing OLAP (on-line analytical processing) to user-analysts: An IT mandate. Technical report, 1993).
In 1995, based on the requirements set out by Codd, the so-called FASMI test (Fast Analysis of Shared Multidimensional Information) was formulated, which includes the following requirements for applications for multidimensional analysis:
· providing the user with analysis results for acceptable time(usually no more than 5 s), even at the cost of less detailed analysis;
· the ability to perform any logical and statistical analysis specific to a given application and save it in a form accessible to the end user;
· multi-user access to data with support for appropriate locking mechanisms and authorized access means;
· multidimensional conceptual representation of data, including full support for hierarchies and multiple hierarchies (this is a key requirement of OLAP);
· opportunity to contact anyone necessary information regardless of its volume and storage location.
It should be noted that OLAP functionality can be implemented in various ways, from the simplest data analysis tools in office applications to distributed analytical systems based on server products. Users can easily view data in a multidimensional structure as it applies to their own problems.
2. What is OLAP
OLAP is an abbreviation for the English On-Line Analytical Processing - this is not the name of a specific product, but of an entire technology. In Russian, it is most convenient to call OLAP operational analytical processing. Although in some publications analytical processing is called both online and interactive, the adjective “online” most accurately reflects the meaning of OLAP technology.
The development of management solutions by a manager falls into the category of areas that are most difficult to automate. However, today there is an opportunity to assist the manager in developing solutions and, most importantly, significantly speed up the process of developing solutions, their selection and adoption. You can use OLAP for this.
Let's look at how the solution development process usually occurs.
Historically, solutions to automate operational activities have been the most developed. We are talking about transactional data processing systems (OLTP), more simply called operational systems. These systems ensure the recording of certain facts, their short-term storage and preservation in archives. The basis of such systems is provided by relational database management systems (RDBMS). The traditional approach is to try to use already built operational systems to support decision making. Usually they try to build a developed system of queries to the operating system and use the reports obtained after interpretation directly to support decisions. Reports can be built on a custom basis, i.e. the manager requests a report, and on a regular basis, when reports are built upon the achievement of certain events or time. For example, a traditional decision support process might look like this: a manager goes to an information specialist and shares his question with him. Then the information department specialist builds a request to the operational system, receives the electronic report, interprets it and then brings it to the attention of management personnel. Of course, such a scheme provides decision support to some extent, but it has extremely low efficiency and a huge number of disadvantages. Minuscule amounts of data are used to support mission-critical decisions. There are other problems too. This process is very slow, since the process of writing requests and interpreting the electronic report is lengthy. It takes many days, at a time when the manager may need to make a decision right now, immediately. If we take into account that the manager, after receiving the report, may be interested in another question (say, clarifying or requiring consideration of data in a different context), then this slow cycle must be repeated, and since the process of analyzing data from operational systems will occur iteratively, even more time is wasted. Another problem is the problem of various areas of activity of a specialist in information technology and the leader, who can think in different categories and, as a result, do not understand each other. Then additional clarifying iterations will be required, and this again is time, which is always in short supply. Another major issue is that reports are difficult to understand. The manager does not have time to select the numbers of interest from the report, especially since there may be too many of them (remember huge multi-page reports in which several pages are actually used, and the rest are used just in case). We also note that the work of interpretation most often falls on specialists in information departments. That is, a competent specialist is distracted by routine and ineffective work of drawing diagrams, etc., which, naturally, cannot have a favorable effect on his qualifications. In addition, it is no secret that in the chain of interpretation there are well-wishers interested in deliberately distorting incoming information.
The above shortcomings make us think about the overall efficiency of the operating system and the costs associated with its existence, since it turns out that the costs of creating an operating system are not adequately compensated by the efficiency of its operation.
In reality, these problems are not a consequence of the poor quality of the operating system or its unsuccessful construction. The roots of the problems lie in the fundamental difference between the operational activities that are automated by the operating system and the activities that develop and make decisions. This difference lies in the fact that operating system data are simply records of certain events and facts that took place, but not information in the general sense of the word. Information is something that reduces uncertainty in any area. And it would be very nice if information reduced uncertainty in the area of decision-making. The well-known E.F. once spoke out about the unsuitability of operating systems built on RDBMS for this purpose. Codd, a pioneer of relational database management system technology in the 1970s: “Although relational database management systems are available to users, they have never been recognized as providing powerful synthesis, analysis and consolidation capabilities (functions called multidimensional data analysis )". We are talking specifically about the synthesis of information, about turning data from operational systems into information and even into qualitative assessments. OLAP makes this transformation possible.
OLAP is based on the idea of a multidimensional data model. Human thinking is multidimensional by definition. When a person asks questions, he imposes restrictions, thereby formulating questions in many dimensions, so the process of analysis in a multidimensional model is very close to the reality of human thinking. According to the dimensions in the multidimensional model, factors influencing the activities of the enterprise are plotted (for example: time, products, company branches, geography, etc.). In this way, a hypercube is obtained (of course, the name is not very successful, since a cube is usually understood as a figure with equal edges, which, in this case, is far from the case), which is then filled with indicators of the enterprise’s activity (prices, sales, plan, profits, losses and etc.). This can be filled with both real data from operating systems and forecast data based on historical data. The dimensions of a hypercube can be complex, hierarchical, and relationships can be established between them. During the analysis process, the user can change the point of view on the data (the so-called operation of changing the logical view), thereby viewing the data from various perspectives and solving specific problems. Various operations can be performed on cubes, including forecasting and conditional planning (what-if analysis). Moreover, the operations are performed simultaneously on the cubes, i.e. the product, for example, will result in a hypercube product, each cell of which is the product of the cells of the corresponding multiplier hypercubes. Naturally, it is possible to perform operations on hypercubes having different numbers of dimensions.
3. History of the creation of OLAP technology
The idea of processing data on multidimensional arrays is not new. In fact, it dates back to 1962, when Ken Iverson published his book “A Programming Language” (APL). The first practical implementation of APL took place in the late sixties by IBM. APL is a very elegant, mathematically defined language with multidimensional variables and processed operations. It was intended to be an original, powerful tool for working with multidimensional transformations compared to other practical programming languages.
However, the idea did not receive mass application for a long time, since the time for graphical interfaces and high-quality printing devices had not yet come, and the display of Greek characters required special screens, keyboards and printing devices. Later, English words were sometimes used to replace Greek operators, but APL purists stopped attempts to popularize their favorite language. APL also consumed machine resources. In those days it was expensive to use. The programs were very slow to execute and, in addition, running them was very expensive. A lot of memory was required, shocking amounts at that time (about 6 MB).
However, the frustration of these initial mistakes did not kill the idea. It was used in many business applications in the 70s, 80s. Many of these applications had features of modern analytical processing systems. Thus, IBM developed an operating system for APL called VSPC, and some people considered it an ideal environment for personal use until spreadsheets became ubiquitous.
But APL was too difficult to use, especially since each time there were inconsistencies between the language itself and the hardware on which attempts were made to implement it.
In the 1980s, APL became available on personal machines, but did not find market use. The alternative was to program multidimensional applications using arrays in other languages. This was a very difficult task even for professional programmers, forcing them to wait for the next generation of multidimensional software products.
In 1972, several multidimensional application software products previously used for educational purposes found commercial use: Express. It remains in a completely rewritten form even now, but the original concepts of the 70s have ceased to be relevant. Today, in the 90s, Express is one of the most popular OLAP technologies, and Oracle(r) will promote it and add new capabilities.
More multidimensional products appeared in the 80s. At the beginning of the decade, a product called Stratagem, later called Acumate (today owned by Kenan Technologies), which was still promoted until the early 90s, but today, unlike Express, is practically not used.
Comshare System W was a multi-dimensional product of a different style. Introduced in 1981, it was the first to focus more on the end user and the development of financial applications. He introduced many concepts that were not well adopted, such as completely non-procedural rules, full-screen viewing and editing of multidimensional data, automatic recalculation, and batch integration with relational data. However, the Comshare System W was quite heavy for the hardware of the time compared to other products and was used less in the future, selling less and less, and no improvements were made to the product. Although it is still available on UNIX, it is not client-server, which does not enhance its offering in the analytics market. In the late 1980s, Comshare released a product for DOS and later for Windows. These products were called Commander Prism and used the same concepts as System W.
Another creative product of the late 80s was called Metaphor. It was intended for professional marketers. He also introduced many new concepts that are just beginning to be widely used today: client-server computing, using a multidimensional model on relational data, object-oriented application development. However, standard personal computer hardware of the day was not capable of running Metaphor, and vendors were forced to develop their own standards for personal computers and networks. Gradually, Metaphor began to work successfully on serial personal machines, but the product was made exclusively for OS/2 and had its own GUI user.
Metaphor then entered into a marketing alliance with IBM, which it subsequently absorbed. In mid-1994, IBM decided to integrate Metaphor technology (renamed DIS) with its future technologies and thereby stop funding a separate line, but customers expressed their displeasure and demanded continued support for the product. Support was continued for remaining customers, and IBM re-released the product under the new name DIS, which, however, did not make it popular. But Metaphor's creative, innovative concepts were not forgotten and are visible in many products today.
In the mid-80s, the term EIS (Executive Information System) was born. The first product to clearly demonstrate this direction was Pilot's Command Center. It was a product that enabled collaborative computing, what we call today client-server computing. Because the power of personal computers in the 1980s was limited, the product was very “server-centric,” but this principle is still very popular today. Pilot did not sell Command Center for long, but it introduced many of the concepts that can be recognized in today's OLAP products, including automatic support for time intervals, multidimensional client-server calculations, and simplified control of the analysis process (mouse, touch screens, etc.). Some of these concepts were reapplied later in Pilot Analysis Server.
Late 80s spreadsheets have been dominant in the market for tools that provide analysis to end users. The first multidimensional spreadsheet was introduced by Compete. It was marketed as a very expensive product for professionals, but the vendors failed to ensure that the product could capture the market, and Computer Associates acquired the rights to it along with other products including Supercalc and 20/20. The main effect of the acquisition of CA Compete was a sharp reduction in its price and the removal of copy protection, which naturally contributed to its distribution. However, it was not successful. Compete is the basis of Supercalc 5, but the multidimensional aspect of it is not promoted. The old Compete is still sometimes used due to the fact that considerable resources were invested in it at one time.
Lotus was the next to try to enter the multidimensional spreadsheet market with its Improv product, which runs on a NeXT machine. This ensured, at a minimum, that sales of 1-2-3 would not decline, but when it was eventually released for Windows, Excel already had a large market share, preventing Lotus from making any changes to the market allocation. Lotus, like CA with Compete, moved Improv to the lower end of the market, but this was not a condition for successful market promotion, and new developments in this area did not continue. It turned out that users personal computers preferred 1-2-3 spreadsheets and are not interested in new multidimensional capabilities unless they are fully compatible with their old spreadsheets. Likewise, the concepts of small, desktop spreadsheets offered as personal applications have not really proven convenient or caught on in the real business world. Microsoft (r) followed this path by adding PivotTables (in the Russian edition this is called “pivot tables”) to Excel. Although few Excel users have benefited from using this feature, it is probably the only evidence of widespread use of multivariate analysis capabilities in the world simply because there are so many Excel users in the world.
4. OLAP, ROLAP, MOLAP…
It is well known that when Codd published his rules for building relational DBMSs in 1985, they caused a strong reaction and subsequently had a strong impact on the DBMS industry in general. However, few people know that in 1993 Codd published a work entitled “OLAP for User Analysts: What It Should Be.” In it, he outlined the basic concepts of online analytics and defined 12 rules that must be met by products that provide online analytics capabilities.
These are the rules (the original text has been preserved whenever possible):
1. Conceptual multidimensional representation. The user-analyst sees the enterprise world as multidimensional in nature. Accordingly, the OLAP model must be multidimensional in its core. A multidimensional conceptual diagram or custom representation facilitates modeling and analysis as well as calculations.
2. Transparency. Whether the OLAP product is part of the user's tools or not, this fact must be transparent to the user. If OLAP is provided by client-server computing, then this fact should also, if possible, be invisible to the user. OLAP must be provided in the context of a truly open architecture, allowing the user, wherever he is, to communicate through an analytical tool with the server. In addition, transparency should be achieved when the analytical tool interacts with homogeneous and heterogeneous database environments.
3. Availability. The OLAP analyst user must be able to perform analyzes based on a common conceptual schema containing enterprise-wide data in a relational database as well as data from legacy legacy databases, common access methods, and a common analytical model. This means that OLAP must provide its own logical schema for access in a heterogeneous database environment and perform appropriate transformations to provide data to the user. Moreover, it is necessary to take care in advance about where and how, and what types of physical organization of data will actually be used. An OLAP system should only access data that is actually needed, rather than adopting a general “kitchen funnel” approach that introduces unnecessary input.
4. Consistent performance in report development. If the number of dimensions or database size increases, the user analyst should not experience any significant degradation in performance. Consistent performance is critical while maintaining end-user ease of use and limiting OLAP complexity. If the user-analyst experiences significant differences in performance according to the number of dimensions, then he will tend to compensate for these differences with the design strategy, which will cause the data to be presented in other ways than the way in which the data actually needs to be presented. Spending time crawling around a system to compensate for its inadequacies is not what analytics products are designed for.
5. Client-server architecture. Most of the data that needs to be processed quickly and analytically today is stored on mainframes with PC access. This means, therefore, that OLAP products must be able to operate in a client-server environment. From this point of view, it is necessary that the server component of the analytical tool be substantially “intelligent” so that various clients can connect to the server with minimal complexity and integration programming. An intelligent server must be able to map and consolidate between disparate logical and physical database schemas. This will provide transparency and build a common conceptual, logical and physical framework.
6. General multidimensionality. Each dimension must be applied without regard to its structure and operational capabilities. Additional operational capabilities can be provided to selected dimensions, and since the dimensions are symmetrical, a single function can be provided to any dimension. Basic data structures, formulas, and reporting formats should not be biased toward any dimension.
7. Dynamic control of sparse matrices. The physical design of an OLAP tool must be fully adapted to the specific analytical model for optimal management of sparse matrices. For any given sparse matrix, there is one and only one optimal physical scheme. This scheme provides maximum memory efficiency and matrix operability, unless, of course, the entire data set does not fit in memory. The underlying physical data of an OLAP tool must be configured to any subset of dimensions, in any order, for practical operations on large analytical models. Physical access methods should also change dynamically and contain different types of mechanisms, such as: direct calculations, B-trees and derivatives, hashing, and the ability to combine these mechanisms if necessary. Sparsity (measured as a percentage empty cells to all possible) is one of the characteristics of data dissemination. Failure to regulate sparsity can make operational efficiency unattainable. If an OLAP tool cannot control and regulate the distribution of the values of the analyzed data, a model that claims to be practical, based on many consolidation paths and dimensions, may in reality be unnecessary and hopeless.
8. Multi-user support. Often, multiple analytic users need to work collaboratively with the same analytic model or create different models from the same data. Therefore, an OLAP tool must provide sharing (query and completion), integrity, and security capabilities.
9. Unlimited cross operations. Different rollup levels and consolidation paths, due to their hierarchical nature, represent dependent relationships in an OLAP model or application. Therefore, the tool itself should imply the corresponding calculations and not require the analytical user to re-define these calculations and operations. Calculations not resulting from these inherited relations require definition by different formulas according to some applicable language. Such a language can allow calculations and manipulation of data of any dimension and not limit the relationships between data cells or pay attention to the number of common data attributes of specific cells.
10. Intuitive data manipulation. Reorientation of consolidation paths, detailing, enlargement and other manipulations regulated by consolidation paths should be applied through a separate impact on the cells of the analytical model, and should not require the use of a menu system or other multiple actions with the user interface. The user-analyst's view of the dimensions defined in the analytical model should contain all the necessary information to perform the above actions.
11. Flexible options for receiving reports. Analysis and presentation of data is simple when the rows, columns and cells of data that will be visually compared with each other will be in proximity to each other or according to some logical function that takes place in the enterprise. Reporting tools must present synthesized data or information resulting from the data model in any possible orientation. This means that rows, columns or pages must show from 0 to N dimensions at a time, where N is the number of dimensions of the entire analytical model. In addition, each content dimension shown in a single post, column, or page must also be able to show any subset of the elements (values) contained in the dimension, in any order.
12. Unlimited dimension and number of aggregation levels. A study on the possible number of necessary dimensions required in an analytical model showed that up to 19 dimensions could be used simultaneously. Hence, it is strongly recommended that the analytical tool be capable of providing at least 15 dimensions simultaneously, and preferably 20. Moreover, each of the common dimensions should not be limited in the number of user-analyst-defined aggregation levels and consolidation paths.
In fact, today's OLAP product developers follow these rules, or at least strive to follow them. These rules can be considered the theoretical basis of operational analytical processing; it is difficult to argue with them. Subsequently, many corollaries were drawn from the 12 rules, which we, however, will not cite, so as not to unnecessarily complicate the narrative.
Let's take a closer look at how OLAP products differ in their physical implementation.
As noted above, OLAP is based on the idea of processing data using multidimensional structures. When we say OLAP, we mean that logically the data structure of the analytical product is multidimensional. How exactly this is implemented is another matter. There are two main types of analytical processing, which include certain products.
MOLAP . Actually multidimensional (multidimensional) OLAP. The product is based on a non-relational data structure that provides multidimensional storage, processing and presentation of data. Accordingly, databases are called multidimensional. Products in this class typically have a multidimensional database server. During the analysis process, data is selected exclusively from a multidimensional structure. Such a structure is highly productive.
ROLAP . Relational OLAP. As the name implies, the multidimensional structure in such tools is implemented by relational tables. And the data in the analysis process, accordingly, is selected from the relational database by an analytical tool.
The disadvantages and advantages of each approach are, in general, obvious. Multidimensional OLAP provides better performance, but structures cannot be used to process large amounts of data, since large dimensions will require large hardware resources, and at the same time, the sparsity of hypercubes can be very high and, therefore, the use of hardware power will not be justified. On the contrary, relational OLAP provides processing on large arrays of stored data, since it is possible to provide more economical storage, but at the same time it is significantly inferior in speed to multidimensional OLAP. Similar reasoning led to the identification of a new class of analytical tools - HOLAP. This is a hybrid operational analytical processing. Tools of this class allow you to combine both approaches - relational and multidimensional. Access can be made to both multidimensional database data and relational data.
There is another rather exotic type of operational analytical processing - DOLAP. This is “desktop” OLAP. We are talking about such analytical processing where hypercubes are small, their dimension is small, the needs are modest, and for such analytical processing a personal machine on a desktop is sufficient.
Operational analytical processing can significantly simplify and speed up the process of preparation and decision-making by management personnel. Online analytical processing serves the purpose of turning data into information. It is fundamentally different from the traditional decision support process, which is most often based on the review of structured reports. By analogy, the difference between structured reports and OLAP is the same as between driving around the city by tram and driving a personal car. When you ride a tram, it moves on rails, which does not allow you to clearly see distant buildings, much less get closer to them. On the contrary, driving a personal car gives you complete freedom of movement (of course, you must follow traffic rules). You can drive up to any building and get to places where trams do not go.
Structured reports are the rails that hinder freedom in preparing decisions. OLAP is a vehicle for efficient movement along information highways.
Conditions of high competition and growing dynamics of the external environment dictate increased demands on enterprise management systems. The development of management theory and practice was accompanied by the emergence of new methods, technologies and models aimed at increasing operational efficiency. Methods and models, in turn, contributed to the emergence of analytical systems. The demand for analytical systems in Russia is high. From the point of view of application, these systems are most interesting in the financial sector: banks, insurance business, investment companies. The results of the work of analytical systems are necessary, first of all, for people on whose decisions the development of the company depends: managers, experts, analysts. Analytical systems allow you to solve problems of consolidation, reporting, optimization and forecasting. To date, no final classification of analytical systems has been developed, nor is there any common system definitions in terms used in this direction. The information structure of an enterprise can be represented by a sequence of levels, each of which is characterized by its own way of processing and managing information, and has its own function in the management process. Thus, analytical systems will be located hierarchically at different levels of this infrastructure.
Transactional systems level
Data Warehouse Layer
Data mart layer
Level of OLAP systems
Analytical application layer
OLAP systems - (OnLine Analytical Processing, analytical processing in the present time) - are a technology for complex multidimensional data analysis. OLAP systems are applicable where there is a task of analyzing multifactor data. They are an effective means of analysis and report generation. The data warehouses, data marts and OLAP systems discussed above belong to business intelligence (BI) systems.
Very often, information and analytical systems created with the expectation of direct use by decision makers turn out to be extremely easy to use, but severely limited in functionality. Such static systems are called in the literature Executive Information Systems (IIS), or Executive Information Systems (EIS). They contain predefined sets of queries and, while sufficient for everyday review, are unable to answer all questions about the available data that may arise when making decisions. The result of such a system, as a rule, is multi-page reports, after careful study of which the analyst has a new series of questions. However, each new request that was not foreseen when designing such a system must first be formally described, coded by the programmer, and only then executed. The waiting time in this case can be hours and days, which is not always acceptable. Thus, the external simplicity of static DSS, for which most customers of information and analytical systems are actively fighting, turns into a catastrophic loss of flexibility.
Dynamic DSS, on the contrary, are focused on processing unregulated (ad hoc) analyst requests for data. The requirements for such systems were considered most deeply by E. F. Codd in the article that laid the foundation for the OLAP concept. The work of analysts with these systems consists of an interactive sequence of forming queries and studying their results.
But dynamic DSS can operate not only in the field of online analytical processing (OLAP); support for making management decisions based on accumulated data can be performed in three basic areas.
Scope of detailed data. This is the scope of most information retrieval systems. In most cases, relational DBMSs cope well with the tasks that arise here. The generally accepted standard for the language for manipulating relational data is SQL. Information retrieval systems that provide an end-user interface in tasks of searching for detailed information can be used as add-ons both over individual databases of transactional systems and over a general data warehouse.
Scope of aggregate indicators. A comprehensive look at the information collected in a data warehouse, its generalization and aggregation, hypercube representation and multidimensional analysis are the tasks of online analytical processing (OLAP) systems. Here you can either focus on special multidimensional DBMS, or remain within the framework of relational technologies. In the second case, pre-aggregated data can be collected in a star-shaped database, or information aggregation can be done on the fly while scanning detailed tables in a relational database.
The sphere of patterns. Intellectual processing is carried out using data mining methods (IDA, Data Mining), the main tasks of which are to search for functional and logical patterns in the accumulated information, build models and rules that explain the found anomalies and/or predict the development of certain processes.
Operational analytical data processing
The OLAP concept is based on the principle of multidimensional data representation. In a 1993 article, E. F. Codd addressed the shortcomings of the relational model, primarily pointing out the inability to “combine, view and analyze data in terms of multiple dimensions, that is, in the most understandable way for enterprise analysts,” and defined the general requirements for OLAP systems that extend functionality of relational DBMS and including multidimensional analysis as one of its characteristics.
Classification of OLAP products according to the method of data presentation.
Currently, there are a large number of products on the market that provide OLAP functionality to one degree or another. About 30 of the most famous are listed on the review Web server http://www.olapreport.com/. Providing a multidimensional conceptual view from the user interface to the source database, all OLAP products are divided into three classes based on the type of source database.
The very first online analytical processing systems (for example, Essbase from Arbor Software, Oracle Express Server from Oracle) belonged to the MOLAP class, that is, they could only work with their own multidimensional databases. They are based on proprietary technologies for multidimensional DBMSs and are the most expensive. These systems provide a full cycle of OLAP processing. They either include, in addition to the server component, their own integrated client interface, or use external programs working with spreadsheets. To maintain such systems, a special staff of employees is required to install, maintain the system, and create data views for end users.
Relational online analytical processing (ROLAP) systems allow data stored in a relational database to be represented in multidimensional form, providing information transformation into a multidimensional model through an intermediate metadata layer. ROLAP systems are well suited for working with large storage facilities. Like MOLAP systems, they require significant maintenance by information technology specialists and involve multi-user operation.
Finally, hybrid systems(Hybrid OLAP, HOLAP) are designed to combine the advantages and minimize the disadvantages inherent in previous classes. Speedware's Media/MR falls into this class. According to the developers, it combines the analytical flexibility and speed of response of MOLAP with the constant access to real data inherent in ROLAP.
Multidimensional OLAP (MOLAP)
In specialized DBMSs based on a multidimensional representation of data, data is organized not in the form of relational tables, but in the form of ordered multidimensional arrays:
1) hypercubes (all cells stored in the database must have the same dimension, that is, be in the most complete measurement basis) or
2) polycubes (each variable is stored with its own set of measurements, and all associated processing difficulties are transferred to the internal mechanisms of the system).
The use of multidimensional databases in online analytical processing systems has the following advantages.
When using multidimensional DBMSs, searching and retrieving data is much faster than with a multidimensional conceptual view of a relational database, since the multidimensional database is denormalized, contains pre-aggregated measures, and provides optimized access to the requested cells.
Multidimensional DBMSs easily cope with the tasks of inclusion in information model various built-in functions, while objectively existing restrictions SQL language make performing these tasks on the basis of relational DBMS quite difficult and sometimes impossible.
On the other hand, there are significant limitations.
Multidimensional DBMSs do not allow working with large databases. In addition, due to denormalization and pre-executed aggregation, the volume of data in a multidimensional database, as a rule, corresponds (according to Codd’s estimate) to 2.5-100 times less than the volume of the original detailed data.
Compared to relational DBMSs, multidimensional DBMSs use external memory very inefficiently. In the vast majority of cases, the information hypercube is highly sparse, and since the data is stored in an ordered form, undefined values can only be removed by choosing the optimal sort order, which allows you to organize the data into the largest possible contiguous groups. But even in this case, the problem is only partially solved. In addition, the optimal sort order for storing sparse data will most likely not be the order that is most often used in queries. Therefore, in real systems it is necessary to seek a compromise between performance and redundancy of disk space occupied by the database.
Consequently, the use of multidimensional DBMS is justified only under the following conditions.
The volume of source data for analysis is not too large (no more than a few gigabytes), that is, the level of data aggregation is quite high.
The set of information dimensions is stable (since any change in their structure almost always requires a complete restructuring of the hypercube).
The system's response time to unregulated requests is the most critical parameter.
Requires extensive use of complex built-in functions to perform cross-dimensional calculations on hypercube cells, including the ability to write custom functions.
Relational OLAP (ROLAP)
The direct use of relational databases in online analytical processing systems has the following advantages.
In most cases, corporate data warehouses are implemented using relational DBMS tools, and ROLAP tools allow analysis directly on them. At the same time, the storage size is not such a critical parameter as in the case of MOLAP.
In the case of a variable dimension problem, when changes to the structure of measurements have to be made quite often, ROLAP systems with dynamic representation of dimensions are the optimal solution, since such modifications do not require physical reorganization of the database.
Relational DBMSs provide significantly more high level data protection and good options for differentiating access rights.
The main disadvantage of ROLAP compared to multidimensional DBMSs is lower performance. To provide performance comparable to MOLAP, relational systems require careful design of the database schema and configuration of indexes, that is, a lot of effort on the part of database administrators. Only by using star schemas can the performance of well-tuned relational systems approach that of systems based on multidimensional databases.
Introduction
Nowadays, almost no organization can do without database management systems, especially among those that are traditionally focused on interacting with customers. Banks, insurance companies, airlines and other transport companies, supermarket chains, telecommunications and marketing firms, organizations engaged in the service sector and others - they all collect and store gigabytes of data about customers, products and services in their databases. The value of such information is undeniable. Such databases are called operational or transactional because they are characterized by a huge number of small transactions, or write-read operations. Computer systems systems that record transactions and actually access transaction databases are usually called online transaction processing systems (OLTP - On-Line Transactional Processing) or accounting systems.
Accounting systems are configured and optimized to perform maximum quantity transactions over short periods of time. Typically, individual transactions are very small and unrelated to each other. However, each data record characterizing interaction with a client (a call to the support service, a cash transaction, an order from a catalog, a visit to the company’s website, etc.) can be used to obtain qualitatively new information, namely to create reports and analyze the company’s activities .
The range of analytical functions in accounting systems is usually very limited. The schemas used in OLTP applications make it difficult to create even simple reports because the data is often distributed across multiple tables and requires complex join operations to aggregate them. In general, attempting to create complex reports requires a lot of processing power and results in lost performance.
In addition, accounting systems store constantly changing data. As transactions are collected, the total values change very quickly, so two analyzes performed within a few minutes of each other may yield different results. Most often, the analysis is performed at the end of the reporting period, otherwise the picture may be distorted. In addition, the data required for analysis can be stored in several systems.
Some analyzes require structural changes that are not feasible in the current operating environment. For example, you need to find out what will happen if the company introduces new products. Such research cannot be carried out on a live base. Consequently, effective analysis can rarely be performed directly in the accounting system.
Decision support systems usually have the means to provide the user with aggregate data for various samples from the original set in a form convenient for perception and analysis. Typically, such aggregate functions form a multidimensional (and therefore non-relational) data set (often called a hypercube or metacube), the axes of which contain parameters, and the cells contain aggregate data that depends on them - and such data can also be stored in relational tables. Along each axis, data can be organized into a hierarchy, representing different levels of detail. Thanks to this data model, users can formulate complex queries, generate reports, and obtain subsets of data.
This is precisely what led to interest in decision support systems, which have become the main area of application of OLAP (On-Line Analytical Processing, operational analytical processing, operational data analysis), turning the “ore” of OLTP systems into a finished “product” that managers and analysts can directly use. This method allows analysts, managers and executives to gain insight into accumulated data through rapid and consistent access to a wide range of information views.
The purpose of the course work is to examine OLAP technology.
multidimensional analytical data processing
Main part
1 Basic information about OLAP
The OLAP concept is based on the principle of multidimensional data representation. Edgar Codd coined the term OLAP in 1993. Having examined the shortcomings of the relational model, he first of all pointed out the impossibility of “combining, viewing and analyzing data from the point of view of multiple dimensions, that is, in the most understandable way for corporate analysts,” and defined the general requirements for OLAP systems that expand the functionality of relational DBMSs and include multidimensional analysis as one of its characteristics.
In a large number of publications, the acronym OLAP denotes not only a multidimensional view of data, but also the storage of the data itself in a multidimensional database. Generally speaking, this is not true, as Codd himself notes that “Relational databases were, are and will be the most suitable technology for storing enterprise data. The need is not for new database technology, but rather for analysis tools that complement the functions of existing DBMSs and sufficient flexible to enable and automate the various types of mining inherent in OLAP." Such confusion leads to oppositions like "OLAP or ROLAP", which is not entirely correct, since ROLAP (relational OLAP) at the conceptual level supports all the functionality defined by the term OLAP. It seems more preferable to use the special term MOLAP for OLAP based on multidimensional DBMSs. According to Codd, a multi-dimensional conceptual view is a multiple perspective consisting of several independent dimensions along which specific sets of data can be analyzed. Simultaneous analysis across multiple dimensions is defined as multivariate analysis. Each dimension includes areas of data consolidation, consisting of a series of successive levels of generalization, where each higher level corresponds to a greater degree of data aggregation for the corresponding dimension. Yes, measurement.
The contractor can be determined by the direction of consolidation, consisting of the levels of generalization “enterprise - division - department - employee”. The Time dimension can even include two consolidation directions - “year - quarter - month - day” and “week - day”, since counting time by month and by week is incompatible. In this case, it becomes possible to arbitrarily select the desired level of detail of information for each of the dimensions. The drilling down operation corresponds to the movement from higher to lower stages of consolidation; on the contrary, the operation of rolling up means movement from lower levels to higher ones.
Codd defined 12 rules that an OLAP class software product must satisfy.
1.2 Requirements for online analytical processing tools
Multi-Dimensional Conceptual View. The conceptual representation of the data model in an OLAP product must be multidimensional in nature, that is, allow analysts to perform intuitive operations of “slice and dice,” rotate, and pivot directions of consolidation. Transparency. The user does not need to know what specific tools are used to store and process data, how the data is organized or where it comes from.
Accessibility. The analyst must be able to perform analysis within the framework of a common conceptual framework, but the data can remain under the control of legacy DBMSs while being tied to a common analytical model. That is, the OLAP tool must overlay its logical schema on the physical data sets, performing all the transformations required to provide a single, consistent, and holistic view of the user's information.
Consistent Reporting Performance. As the number of dimensions and database sizes increase, analysts should not experience any performance degradation. Sustained performance is necessary to maintain the ease of use and freedom from complexity that is required to bring OLAP to the end user.
Client - server architecture (Client-Server Architecture). Most of the data that requires rapid analytical processing is stored in mainframe systems and retrieved from personal computers. Therefore, one of the requirements is the ability of OLAP products to work in a client-server environment. The main idea here is that the server component of an OLAP tool must be intelligent enough and have the ability to build a common conceptual schema by summarizing and consolidating the various logical and physical schemas of enterprise databases to provide a transparent effect.
Generic Dimensionality. All data dimensions must be equal. Additional functionality can be provided to individual dimensions, but since they are all symmetrical, this additional functionality can be provided to any dimension. The underlying data structure, formulas, and reporting formats should not rely on any one dimension.
Dynamic Sparse Matrix Handling. An OLAP tool must provide optimal processing of sparse matrices. The access speed must be maintained regardless of the location of the data cells and be constant for models with different numbers of dimensions and different data sparsity.
Multi-User Support. Often, several analysts need to work simultaneously with one analytical model or create different models based on the same corporate data. The OLAP tool must provide them with concurrent access and ensure data integrity and security.
Unrestricted Cross-dimensional Operations support. Computations and manipulation of data along any number of dimensions must not prohibit or restrict any relationships between data cells. Transformations that require arbitrary definition must be specified in a functionally complete formula language.
Intuitive Data Manipulation. Reorientation of consolidation directions, data detailing in columns and rows, aggregation and other manipulations inherent in the structure of the hierarchy of consolidation directions should be performed in the most convenient, natural and comfortable user interface.
Flexible reporting mechanism. Various ways of visualizing data must be supported, that is, reports must be presented in every possible orientation.
Unlimited Dimensions and Aggregation Levels. It is strongly recommended that every serious OLAP tool assume at least fifteen, and preferably twenty, dimensions in the analytical model.
2 Components of OLAP systems
2.1 Server. Client. Internet
OLAP allows you to perform fast and efficient analysis on large volumes of data. Data is stored in a multi-dimensional form that most closely reflects the natural state of real-world business data. OLAP also provides users with the ability to aggregate data faster and easier. With it, they can drill down into the content of this data if necessary to obtain more detailed information.
An OLAP system consists of many components. At the highest level of presentation, the system includes a data source, an OLAP server and a client. A data source represents the source from which the data for analysis is taken. Data from the source is transferred or copied to the OLAP server, where it is systematized and prepared for faster generation of responses to queries. The client is the user interface to the OLAP server. This section of the article describes the functions of each component and the significance of the entire system as a whole. Sources. The source in OLAP systems is the server that supplies data for analysis. Depending on the area of use of the OLAP product, the source may be a Data Warehouse, a legacy database containing common data, a set of tables combining financial data, or any combination of the above. The ability of an OLAP product to work with data from various sources is very important. Requiring a single format or a single database in which all source data is stored is not suitable for database administrators. In addition, this approach reduces the flexibility and power of the OLAP product. Administrators and users believe that OLAP products that can retrieve data from not only multiple sources but multiple sources are more flexible and useful than those with more stringent requirements.
Server. The application part of the OLAP system is the OLAP server. This component does all the work (depending on the system model), and stores all the information to which active access is provided. Server architecture is governed by various concepts. In particular, the main functional characteristic of an OLAP product is the use of a multidimensional (MMDB) or relational (RDB) database for data storage. Aggregated/Pre-aggregated data
Fast query implementation is an imperative for OLAP. This is one of the basic principles of OLAP - the ability to intuitively manipulate data requires rapid retrieval of information. In general, the more calculations that must be made to obtain a piece of information, the slower the response. Therefore, in order to keep query implementation time short, pieces of information that are usually accessed most often, but which also require calculation, are subject to preliminary aggregation. That is, they are counted and then stored in the database as new data. An example of the type of data that can be calculated in advance is summary data - for example, sales figures for months, quarters or years, for which the actual data entered is daily figures.
Various suppliers adhere to various methods selection of parameters that require preliminary aggregation and the number of pre-calculated values. The aggregation approach affects both the database and query execution time. If more values are being calculated, the likelihood that the user will request a value that has already been calculated increases, and therefore response time will be reduced by not having to request the original value to be calculated. However, if you calculate all possible values - this is not the best solution - in this case the size of the database increases significantly, which will make it unmanageable, and the aggregation time will be too long. In addition, when numerical values are added to the database, or if they change, this information must be reflected in pre-calculated values that depend on the new data. Thus, updating the database can also take a long time in the case of a large number of pre-calculated values. Since the database typically runs offline during aggregation, it is desirable that the aggregation time is not too long.
Client. The client is exactly what is used to present and manipulate data in the database. The client can be quite simple - in the form of a table that includes such OLAP capabilities as, for example, data rotation (pivoting) and deepening into data (drilling), and represent a specialized, but equally simple report viewer or be such as powerful a tool as a custom application designed for complex data manipulation. The Internet is a new form of client. In addition, it bears the stamp of new technologies; Many Internet solutions differ significantly in their capabilities in general and as an OLAP solution in particular. This section discusses the various functional properties of each client type.
Despite the fact that the server is the “backbone” of an OLAP solution, the client is no less important. The server can provide a strong foundation to facilitate data manipulation, but if the client is complex or limited in functionality, the user will not be able to take full advantage of the powerful server. The customer is so important that many vendors focus their efforts solely on customer development. Everything that is included in these applications is a standard look at the interface, predefined functions and structure, and quick solutions for more or less standard situations. For example, financial packages are popular. Pre-built financial applications allow professionals to use familiar financial tools without having to design a database structure or conventional forms and reports. Query Tool/Report Generator. A query tool or report generator offers easy access to OLAP data. They have an easy-to-use graphical interface and allow users to create reports by drag-and-dropping objects into the report. While a traditional report generator provides the user with the ability to quickly produce formatted reports, OLAP-enabled report generators produce up-to-date reports. The final product is a report that has the ability to drill down into data to the level of detail, rotate (pivot) reports, support hierarchies, etc. Add-Ins (additions) of spreadsheets.
Today, many lines of business use spreadsheets to perform various forms of corporate data analysis. In some ways, it is an ideal tool for creating reports and viewing data. The analyst can create macros that manipulate data in a specific direction, and the template can be designed so that when data is entered, the formulas calculate the correct values, eliminating the need to repeatedly enter simple calculations.
However, all this results in a "flat" report, which means that once it is created, it is difficult to examine it from different aspects. For example, a chart displays information for a certain time period, say, a month. And if one wants to see daily data (as opposed to monthly data), an entirely new chart will need to be created. There are new data sets to define, new labels to add to the chart, and many other simple but time-consuming changes to make. In addition, there are a number of areas where errors can be made, which overall reduces reliability. When OLAP is added to a table, it becomes possible to create a single chart and then manipulate it in various ways to provide the user with necessary information without the burden of creating every possible representation. Internet as a client. The newest member of the OLAP client family is the Internet. There are many advantages to generating OLAP reports over the Internet. The most significant seems to be the absence of the need for specialized software to access information. This saves the company a lot of time and money.
Each Internet product is specific. Some make it easier to create Web pages, but have less flexibility. Others let you create views of the data and then save them as static HTML files. All this makes it possible to view data via the Internet, but nothing more. It is impossible to actively manipulate data with their help.
There is another type of product - interactive and dynamic, which turns such products into fully functional tools. Users can drill into data, pivot, limit dimensions, and more. Before choosing a Web enabler, it is important to understand what functionality is required from a Web solution and then determine which product will best implement that functionality.
Applications. Applications are a type of client that uses databases OLAP data. They are identical to the query tools and report generators described above, but in addition they bring greater functionality to the product. The application is generally more powerful than the query tool.
Development. Typically, OLAP providers provide a development environment for users to create their own customized applications. The development environment as a whole is a graphical interface that supports object-oriented application development. In addition, most vendors provide an API that can be used to integrate OLAP databases with other applications.
2.2 OLAP clients
OLAP clients with a built-in OLAP engine are installed on users' PCs. They require no server for computing and have zero administration involved. Such clients allow the user to tune into his existing databases; As a rule, a dictionary is created that hides the physical structure of the data behind its subject description, understandable to a specialist. After this, the OLAP client executes arbitrary queries and displays the results in an OLAP table. In this table, in turn, the user can manipulate the data and receive hundreds of different reports on the screen or on paper. OLAP clients designed to work with RDBMSs allow you to analyze data already available in the corporation, for example, stored in an OLTP database. However, their second purpose may be to quickly and cheaply create warehouses or data marts - in this case, the organization's programmers only need to create sets of star tables in relational databases and data loading procedures. The most time-consuming part of the work - writing interfaces with numerous options for custom queries and reports - is implemented in the OLAP client in just a few hours. The end user needs about 30 minutes to master such a program. OLAP clients are supplied by database developers themselves, both multidimensional and relational. These are SAS Corporate Reporter, which is almost a standard product in terms of convenience and beauty, Oracle Discoverer, a set of programs MS Pivot Services and Pivot Table, etc. Many programs designed to work with MS OLAP Services are delivered as part of the “OLAP to the Masses” campaign, which conducted by Microsoft Corporation. As a rule, they are improved versions of Pivot Table and are designed for use in MS Office or a Web browser. These are products from Matryx, Knosys, etc., which, due to their simplicity, cheapness and efficiency, have gained immense popularity in the West.
3 Classification of OLAP products
3.1 Multidimensional OLAP
Currently, there are a large number of products on the market that provide OLAP functionality to one degree or another. Providing a multidimensional conceptual view from the user interface to the source database, all OLAP products are divided into three classes based on the type of source database.
1. The very first online analytical processing systems (for example, Essbase from Arbor Software, Oracle Express Server from Oracle) belonged to the MOLAP class, that is, they could only work with their own multidimensional databases. They are based on proprietary technologies for multidimensional DBMSs and are the most expensive. These systems provide a full cycle of OLAP processing. They either include, in addition to the server component, their own integrated client interface, or use external spreadsheet programs to communicate with the user. To maintain such systems, a special staff of employees is required to install, maintain the system, and create data views for end users.
2. Relational online analytical processing (ROLAP) systems allow data stored in a relational database to be represented in multidimensional form, providing transformation of information into a multidimensional model through an intermediate metadata layer. This class includes MicroStrategy's DSS Suite, Informix's MetaCube, Information Advantage's DecisionSuite, and others. The InfoVisor software package, developed in Russia, at the Ivanovo State Energy University, is also a system of this class. ROLAP systems are well suited for working with large storage facilities. Like MOLAP systems, they require significant maintenance by information technology specialists and involve multi-user operation.
3. Finally, hybrid systems (Hybrid OLAP, HOLAP) are designed to combine the advantages and minimize the disadvantages inherent in previous classes. Speedware's Media/MR falls into this class. According to the developers, it combines the analytical flexibility and speed of response of MOLAP with the constant access to real data inherent in ROLAP.
In addition to the listed tools, there is another class - tools for generating queries and reports for desktop PCs, supplemented with OLAP functions or integrated with external tools that perform such functions. These well-developed systems retrieve data from original sources, transform it and place it into a dynamic multi-dimensional database running on the end user's client station. The main representatives of this class are BusinessObjects from the company of the same name, BrioQuery from Brio Technology, and PowerPlay from Cognos. An overview of some OLAP products is provided in the appendix.
In specialized DBMSs based on a multidimensional representation of data, data is organized not in the form of relational tables, but in the form of ordered multidimensional arrays:
1) hypercubes (all cells stored in the database must have the same dimension, that is, be in the most complete measurement basis) or
2) polycubes (each variable is stored with its own set of measurements, and all associated processing difficulties are transferred to the internal mechanisms of the system).
The use of multidimensional databases in online analytical processing systems has the following advantages.
1. In the case of using multidimensional DBMS, searching and retrieving data is much faster than with a multidimensional conceptual view of a relational database, since the multidimensional database is denormalized, contains pre-aggregated indicators and provides optimized access to the requested cells.
2. Multidimensional DBMSs easily cope with the tasks of including various built-in functions in the information model, while objectively existing limitations of the SQL language make performing these tasks on the basis of relational DBMSs quite difficult and sometimes impossible.
On the other hand, there are significant limitations.
1. Multidimensional DBMSs do not allow working with large databases. In addition, due to denormalization and pre-executed aggregation, the volume of data in a multidimensional database, as a rule, corresponds (according to Codd’s estimate) to 2.5-100 times less than the volume of the original detailed data.
2. Multidimensional DBMSs, compared to relational ones, use external memory very inefficiently. In the vast majority of cases, the information hypercube is highly sparse, and since the data is stored in an ordered form, undefined values can only be removed by choosing the optimal sort order, which allows you to organize the data into the largest possible contiguous groups. But even in this case, the problem is only partially solved. In addition, the optimal sort order for storing sparse data will most likely not be the order that is most often used in queries. Therefore, in real systems it is necessary to seek a compromise between performance and redundancy of disk space occupied by the database.
Consequently, the use of multidimensional DBMS is justified only under the following conditions.
1. The volume of initial data for analysis is not too large (no more than a few gigabytes), that is, the level of data aggregation is quite high.
2. The set of information dimensions is stable (since any change in their structure almost always requires a complete restructuring of the hypercube).
3. The system's response time to unregulated requests is the most critical parameter.
4. Requires extensive use of complex built-in functions to perform cross-dimensional calculations on hypercube cells, including the ability to write custom functions.
The direct use of relational databases in online analytical processing systems has the following advantages.
1. In most cases, corporate data warehouses are implemented using relational DBMS, and ROLAP tools allow analysis directly on them. At the same time, the storage size is not such a critical parameter as in the case of MOLAP.
2. In the case of a variable dimension of the problem, when changes to the measurement structure have to be made quite often, ROLAP systems with dynamic representation of dimensions are the optimal solution, since such modifications do not require physical reorganization of the database.
3. Relational DBMSs provide a significantly higher level of data protection and good options for delineating access rights.
The main disadvantage of ROLAP compared to multidimensional DBMSs is lower performance. To provide performance comparable to MOLAP, relational systems require careful design of the database schema and configuration of indexes, that is, a lot of effort on the part of database administrators. Only by using star schemas can the performance of well-tuned relational systems approach that of systems based on multidimensional databases.
The works are entirely devoted to the description of the star schema and recommendations for its use. The idea is that there are tables for each dimension, and all the facts are placed in one table, indexed by a multiple key made up of the keys of the individual dimensions (Appendix A). Each ray of the star diagram specifies, in Codd's terminology, the direction of data consolidation along the corresponding dimension.
In complex problems with multi-level dimensions, it makes sense to turn to extensions of the star schema - the constellation schema (fact constellation schema) and the snowflake schema (snowflake schema). In these cases, separate fact tables are created for possible combinations of summary levels of different dimensions (Appendix B). This allows for better performance, but often leads to data redundancy and significant complexity in the database structure, which contains a huge number of fact tables.
An increase in the number of fact tables in a database can stem not only from the multiplicity of levels of different dimensions, but also from the fact that, in general, facts have different sets of dimensions. When abstracting from individual measurements, the user must receive a projection of the most complete hypercube, and the values of the indicators in it are not always the result of elementary summation. Thus, with a large number of independent dimensions, it is necessary to maintain many fact tables corresponding to each possible combination of dimensions selected in the query, which also leads to wasteful use external memory, increased time for loading data into the star schema database from external sources and administration difficulties.
Extensions to the SQL language partially solve this problem (the GROUP BY CUBE, GROUP BY ROLLUP, and GROUP BY GROUPING SETS statements); in addition, a mechanism is proposed to find a compromise between redundancy and performance, recommending creating fact tables not for all possible combinations of dimensions , but only for those whose cell values cannot be obtained using subsequent aggregation of more complete fact tables (Appendix B).
In any case, if the multidimensional model is implemented as a relational database, you should create long and "narrow" fact tables and relatively small and "wide" dimension tables. Fact tables contain the numerical values of the hypercube cells, and the remaining tables define the multidimensional measurement basis containing them. Some information can be obtained using dynamic aggregation of data distributed over non-star normalized structures, although it should be remembered that queries involving aggregation in a highly normalized database structure can be quite slow.
Focusing on the representation of multidimensional information using star-shaped relational models allows us to get rid of the problem of optimizing the storage of sparse matrices, which is acute for multidimensional DBMSs (where the sparsity problem is solved by a special choice of schema). Although each cell is used to store whole post, which, in addition to the values themselves, includes secondary keys - links to dimension tables; non-existent values are simply not included in the fact table.
Conclusion
Having considered the issues of operation and application of OLAP technology, companies face questions, the answers to which will allow them to choose a product that best meets the user’s needs.
These are the following questions:
Where does the data come from? – The data to be analyzed may be located in different places. It is possible that the OLAP database will receive them from an enterprise data warehouse or from an OLTP system. If the OLAP product already has the ability to access some data source, the processes of categorizing and cleaning data are reduced.
What manipulations does the user perform on the data? -
Once a user has accessed the database and started performing analysis, it is important that they are able to manipulate the data appropriately. Depending on the user's needs, it may be that a powerful report generator or the ability to create and host dynamic web pages is needed. However, it may be preferable for the user to have at his disposal a means of easily and quickly creating his own applications.
What is the total amount of data? - This is the most important factor when defining an OLAP database. Relational OLAP products can handle large amounts of data better than multidimensional ones. If the volume of data does not require the use of a relational database, a multidimensional product can be used with equal success.
Who is the user? - When defining an OLAP system client, the user's skill level is important. Some users are more comfortable integrating OLAP with a table, while others will prefer a dedicated application. Depending on the user’s qualifications, the issue of conducting training is also decided. A large company may wish to pay for user training, the company smaller size may refuse them. The client should be such that users feel confident and can use it effectively.
Today, most of the world's companies have moved to using OLAP as the core technology to provide information to decision makers. Therefore, the fundamental question to ask is whether spreadsheets should continue to be used as the primary platform for reporting, budgeting and forecasting. Companies must ask themselves if they are willing to lose competitive advantages, using inaccurate, irrelevant and incomplete information before they mature and consider alternative technologies.
Also, in conclusion, it should be noted that the analytical capabilities of OLAP technologies increase the usefulness of data stored in a corporate information warehouse, allowing a company to interact more effectively with its customers.
Glossary
| Concept | Definition | |
| 1 | BI tools | Tools and technologies used to access information. Includes OLAP technologies, data mining and complex analysis; end-user tools and ad hoc query tools, business monitoring dashboards and corporate reporting generators. |
| 2 | On-line Analytical Processing, OLAP (Operational Analytical Processing) | Technology for analytical processing of information in real time, including the compilation and dynamic publication of reports and documents. |
| 3 | Slice and Dice (Longitudinal and transverse sections, literally - “cutting into slices and cubes”) | A term used to describe the complex data analysis functionality provided by OLAP tools. Retrieving data from a multidimensional cube with specified values and a specified relative arrangement of dimensions. |
| 4 | Data Pivot | The process of rotating a table of data, that is, converting columns to rows and vice versa. |
| 5 | Calculated member | A measurement element whose magnitude is determined by the magnitudes of other elements (for example, in mathematical or logical applications). The calculated element may be part of an OLAP server or described by the user during an interactive session. A calculated element is any element that is not entered but is calculated. |
| 6 | Global Business Models | A type of data warehouse that provides access to information that is distributed across various systems enterprise and is under the control of different divisions or departments with different databases and data models. This type of Data Warehouse is difficult to build due to the need to combine the efforts of users from different departments to develop a common data model for the Warehouse. |
| 7 | Data Mining | Technical techniques using software tools designed for such a user who, as a rule, cannot say in advance what exactly he is looking for, but can only indicate certain patterns and directions of search. |
| 8 | Client/Server | A technological approach that consists in dividing the process into separate functions. The server performs several functions - managing communications, providing database maintenance, etc. The client performs individual user functions - providing appropriate interfaces, performing cross-screen navigation, providing help functions, etc. |
| 9 | Multi-dimensional Database, MDBS and MDBMS | A powerful database that allows users to analyze large amounts of data. A database with a special storage organization - cubes, providing high speed working with data stored as a collection of facts, dimensions and pre-calculated aggregates. |
| 10 | Drill Down | A method of examining detailed data used to analyze the summary level of data. The levels of "deepening" depend on the level of detail of the data in [ran. |
| 11 | Central Warehouse | 1. Database containing data collected from operating systems organizations. It has a structure convenient for data analysis. Designed to support decision making and create a unified information space corporations. 2. An automation method that covers all information systems managed from one place. |
1 Golitsina O.L., Maksimov N.V., Popov I.I. Database: Tutorial. – M.: FORUM: INFRA-M, 2003. – 352 p.
2 Date K. Introduction to database systems. – M.: Nauka, 2005 – 246 p.
3 Elmanova N.V., Fedorov A.A. Introduction to Microsoft OLAP technologies. – M.: Dialogue-MEPhI, 2004. – 312 p.
4 Karpova T.S. Databases: models, development, implementation. – St. Petersburg: Peter, 2006. – 304 p.
5 Korovkin S. D., Levenets I. A., Ratmanova I. D., Starykh V. A., Shchavelev L. V. Solution to the problem of complex operational analysis of information from data warehouses // DBMS. - 2005. - No. 5-6. - 47-51 s.
6 Krechetov N., Ivanov P. Products for data mining ComputerWeek-Moscow. - 2003. - No. 14-15. - 32-39 s.
7 Przhiyalkovsky V.V. Complex analysis of large-volume data: new prospects for computerization // DBMS. - 2006. - No. 4. - 71-83 p.
8 Sakharov A. A. Concept of construction and implementation of information systems focused on data analysis // DBMS. - 2004. - No. 4. - 55-70 p.
9 Ullman J. Fundamentals of database systems. – M.: Finance and Statistics, 2003. – 312 p.
10 Hubbard J. Computer-aided design databases. – M.: Mir, 2007. – 294 p.
Korovkin S. D., Levenets I. A., Ratmanova I. D., Starykh V. A., Shchavelev L. V. Solution of the problem of complex operational analysis of information from data warehouses // DBMS. - 2005. - No. 5-6. - 47-51 s.
Ullman J. Fundamentals of database systems. – M.: Finance and Statistics, 2003. – 312 p.
Barseghyan A.A., Kupriyanov M.S. Data analysis technologies: DataMining, VisualMining, TextMining, Olap. – St. Petersburg: BHV-Petersburg, 2007. – 532 p.
Elmanova N.V., Fedorov A.A. Introduction to Microsoft OLAP technologies. – M.: Dialogue-MEPhI, 2004. – 312 p.
Date K. Introduction to database systems. – M.: Nauka, 2005 – 246 p.
Golitsina O.L., Maksimov N.V., Popov I.I. Databases: Textbook. – M.: FORUM: INFRA-M, 2003. – 352 p.
Sakharov A. A. Concept of construction and implementation of information systems focused on data analysis // DBMS. - 2004. - No. 4. - 55-70 p.
Przhiyalkovsky V.V. Complex analysis of large-volume data: new prospects for computerization // DBMS. - 2006. - No. 4. - 71-83 p.
The concept of OLAP technology was formulated by Edgar Codd in 1993.
This technology is based on the construction of multidimensional data sets - so-called OLAP cubes (not necessarily three-dimensional, as one might conclude from the definition). The purpose of using OLAP technologies is to analyze data and present this analysis in a form convenient for management personnel to understand and make decisions based on them.
Basic requirements for applications for multivariate analysis:
- - providing the user with analysis results in an acceptable time (no more than 5 s);
- - multi-user access to data;
- - multidimensional data presentation;
- - the ability to access any information regardless of its storage location and volume.
OLAP system tools provide the ability to sort and select data according to specified conditions. Various qualitative and quantitative conditions can be specified.
The main data model used in numerous tools ah creation and support of databases - DBMS is a relational model. The data in it is presented in the form of a set of two-dimensional relation tables connected by key fields. To eliminate duplication, inconsistency, and reduce labor costs for maintaining databases, a formal apparatus for normalizing entity tables is used. However, its use is associated with additional time spent on generating responses to database queries, although memory resources are saved.
A multidimensional data model represents the object under study in the form of a multidimensional cube; a three-dimensional model is more often used. Dimensions or attribute details are plotted along the axes or faces of the cube. The base attributes are the filling of the cube cells. A multidimensional cube can be represented by a combination of three-dimensional cubes in order to facilitate perception and presentation when generating reporting and analytical documents and multimedia presentations based on analytical work materials in a decision support system.
Within the framework of OLAP technologies, based on the fact that a multidimensional representation of data can be organized both by means of relational DBMSs and multidimensional specialized tools, three types of multidimensional OLAP systems are distinguished:
- - multidimensional OLAP-MOLAP;
- - relational OLAP-ROLAP;
- - mixed or hybrid (Hibrid) OLAP-HOLAP.
In multidimensional DBMSs, data is organized not in the form of relational tables, but in the form of ordered multidimensional arrays in the form of hypercubes, when all stored data must have the same dimension, which means the need to form the most complete basis of dimensions. Data can be organized in the form of polycubes; in this option, the values of each indicator are stored with its own set of dimensions, and data processing is carried out by the system’s own tool. The storage structure in this case is simplified, because there is no need for a data storage area in a multidimensional or object-oriented form. Huge labor costs for creating models and systems for converting data from a relational model to an object model are reduced.
The advantages of MOLAP are:
- - faster receipt of responses to requests than with ROLAP - the time spent is one or two orders of magnitude less;
- - because of SQL restrictions Implementation of many built-in functions becomes difficult.
Limitations of MOLAP include:
- - relatively small database sizes;
- - due to denormalization and pre-aggregation multidimensional arrays use 2.5-100 times more memory than the original data (memory consumption increases exponentially as the number of measurements increases);
- - there are no standards for the interface and means of data manipulation;
- - there are restrictions when loading data.
Labor costs for creating multidimensional data increase sharply, because... In this situation, there are practically no specialized means of objectifying the relational model of data contained in the information repository. Query response times often cannot meet the requirements for OLAP systems.
The advantages of ROLAP systems are:
- - the ability to quickly analyze the data directly contained in the warehouse, because most source databases are relational;
- - with a variable dimension of the problem, RO-LAP wins, because no physical reorganization of the database is required;
- - ROLAP systems can use less powerful client stations and servers, and the servers bear the main burden of processing complex SQL queries;
- - the level of information protection and differentiation of access rights in relational DBMSs is incomparably higher than in multidimensional ones.
The disadvantage of ROLAP systems is lower performance, the need for careful development of database schemas, special setting indexes, analysis of query statistics and taking into account the analysis findings when modifying database schemas, which leads to significant additional labor costs.
Fulfillment of these conditions allows, when using ROLAP systems, to achieve indicators similar to MOLAP systems in terms of access time, as well as surpass them in memory savings.
Hybrid OLAP systems are a combination of tools that implement a relational and multidimensional data model. This allows you to dramatically reduce the resource costs of creating and maintaining such a model and the response time to requests.
This approach uses the advantages of the first two approaches and compensates for their disadvantages. This principle is implemented in the most developed software products for this purpose.
The use of hybrid architecture in OLAP systems is the most appropriate way to solve problems associated with the use of software tools in multidimensional analysis.
The pattern detection mode is based on intelligent data processing. The main task here is to identify patterns in the processes under study, relationships and mutual influence of various factors, search for large “unusual” deviations, and predict the course of various significant processes. This area relates to data mining.