OLAP-технология. Курсовая работа: Технология OLAP В каком году появились первые olap системы
OLAP (от англ. OnLine Analytical Processing - оперативная аналитическая обработка данных, также: аналитическая обработка данных в реальном времени, интерактивная аналитическая обработка данных) - подход к аналитической обработке данных, базирующийся на их многомерном иерархическом представлении, являющийся частью более широкой области информационных технологий - бизнес-аналитики ().
Каталог OLAP-решений и проектов смотрите в разделе OLAP на TAdviser.
С точки зрения пользователя, OLAP -системы представляют средства гибкого просмотра информации в различных срезах, автоматического получения агрегированных данных, выполнения аналитических операций свёртки, детализации, сравнения во времени. Всё это делает OLAP-системы решением с очевидными преимуществами в области подготовки данных для всех видов бизнес-отчетности, предполагающих представление данных в различных разрезах и разных уровнях иерархии - например, отчетов по продажам, различных форм бюджетов и так далее. Очевидны плюсы подобного представления и в других формах анализа данных, в том числе для прогнозирования.
Требования к OLAP-системам. FASMI
Ключевое требование, предъявляемое к OLAP-системам - скорость, позволяющая использовать их в процессе интерактивной работы аналитика с информацией. В этом смысле OLAP-системы противопоставляются, во-первых, традиционным РСУБД , выборки из которых с типовыми для аналитиков запросами, использующими группировку и агрегирование данных, обычно затратны по времени ожидания и загрузке РСУБД , поэтому интерактивная работа с ними при сколько-нибудь значительных объемах данных сложна. Во-вторых, OLAP-системы противопоставляются и обычному плоскофайловому представлению данных, например, в виде часто используемых традиционных электронных таблиц, представление многомерных данных в которых сложно и не интуитивно, а операции по смене среза - точки зрения на данные - также требуют временных затрат и усложняют интерактивную работу с данными.
При этом, с одной стороны, специфичные для OLAP-систем требования к данным обычно подразумевают хранение данных в специальных оптимизированных под типовые задачи OLAP структурах, с другой сторны, непосредственное извлечение данных из существующих систем в процессе анализа привело бы к существенному падению их производительности.
Следовательно, важным требованием является обеспечение макимально гибкой связки импорта-экспорта между существующими системами, выступающими в качестве источника данных и OLAP-системой, а также OLAP-системой и внешними приложениями анализа данных и отчетности.
При этом такая связка должна удовлетворять очевидным требованиям поддержки импорта-экспорта из нескольких источников данных, осуществления процедур очистки и трансформации данных, унификации используемых классификаторов и справочников. Кроме того, к этим требованиям добавляется необходимость учёта различных циклов обновления данных в существующих информационных системах и унификации требуемого уровня детализации данных. Сложность и многогранность этой проблемы привела к появлению концепции хранилищ данных , и, в узком смысле, к выделению отдельного класса утилит конвертации и преобразования данных - ETL (Extract Transform Load) .
Модели хранения активных данных
Выше мы указали, что OLAP предполагает многомерное иерархическое представление данных, и, в каком-то смысле, противопоставляется базирующимся на РСУБД системам.
Это, однако, не значит, что все OLAP-системы используют многомерную модель для хранения активных, "рабочих" данных системы. Так как модель хранения активных данных оказывает влияние на все диктуемые FASMI-тестом требования, её важность подчёркивается тем, что именно по этому признаку традиционно выделяют подтипы OLAP - многомерный (MOLAP), реляционный (ROLAP) и гибридный (HOLAP).
Вместе с тем, некоторые эксперты, во главе с вышеупомянутым Найджелом Пендсом , указывают, что классификация, базирующаяся на одном критерии недостаточно полна. Тем более, что подавляющее большинство существующих OLAP-систем будут относиться к гибридному типу. Поэтому мы более подробно остановимся именно на моделях хранения активных данных, упомянув, какие из них соответствуют каким из традиционных подтипов OLAP.
Хранение активных данных в многомерной БД
В этом случае данные OLAP хранятся в многомерных СУБД , использующих оптимизированные для такого типа данных конструкции. Обычно многомерные СУБД поддерживают и все типовые для OLAP операции, включая агрегацию по требуемым уровням иерархии и так далее.
Этот тип хранения данных в каком-то смысле можно назвать классическим для OLAP. Для него, впрочем, в полной мере необходимы все шаги по предварительной подготовке данных. Обычно данные многомерной СУБД хранятся на диске, однако, в некоторых случаях, для ускорения обработки данных такие системы позволяют хранить данные в оперативной памяти . Для тех же целей иногда применяется и хранение в БД заранее рассчитанных агрегатных значений и прочих расчётных величин.
Многомерные СУБД , полностью поддерживающие многопользовательский доступ с конкурирующими транзакциями чтения и записи достаточно редки, обычным режимом для таких СУБД является однопользовательский с доступом на запись при многопользовательском на чтение, либо многопользовательский только на чтение.
Среди условных недостатков, характерных для некоторых реализаций многомерных СУБД и базирующихся на них OLAP-систем можно отметить их подверженность непредсказуемому с пользовательской точки зрения росту объёмов занимаемого БД места. Этот эффект вызван желанием максимально уменьшить время реакции системы, диктующим хранить заранее рассчитанные значения агрегатных показателей и иных величин в БД, что вызывает нелинейный рост объёма хранящейся в БД информации с добавлением в неё новых значений данных или измерений.
Степень проявления этой проблемы, а также связанных с ней проблем эффективного хранения разреженных кубов данных, определяется качеством применяемых подходов и алгоритмов конкретных реализаций OLAP-систем.
Хранение активных данных в реляционной БД
Могут храниться данные OLAP и в традиционной РСУБД . В большинстве случаев этот подход используется при попытке «безболезненной» интеграции OLAP с существующими учётными системами, либо базирующимися на РСУБД хранилищами данных . Вместе с тем, этот подход требует от РСУБД для обеспечения эффективного выполнения требований FASMI-теста (в частности, обеспечения минимального времени реакции системы) некоторых дополнительных возможностей. Обычно данные OLAP хранятся в денормализованном виде, а часть заранее рассчитанных агрегатов и значений хранится в специальных таблицах. При хранении же в нормализованном виде эффективность РСУБД в качестве метода хранения активных данных снижается.
Проблема выбора эффективных подходов и алгоритмов хранения предрассчитанных данных также актуальна для OLAP-систем, базирующихся на РСУБД, поэтому производители таких систем обычно акцентируют внимание на достоинствах применяемых подходов.
В целом считается, что базирующиеся на РСУБД OLAP-системы медленнее систем, базирующихся на многомерных СУБД, в том числе за счет менее эффективных для задач OLAP структур хранения данных, однако на практике это зависит от особенностей конкретной системы.
Среди достоинств хранения данных в РСУБД обычно называют большую масштабируемость таких систем.
Хранение активных данных в «плоских» файлах
Этот подход предполагает хранение порций данных в обычных файлах. Обычно он используется как дополнение к одному из двух основных подходов с целью ускорения работы за счет кэширования актуальных данных на диске или в оперативной памяти клиентского ПК.
Гибридный подход к хранению данных
Большинство производителей OLAP-систем, продвигающих свои комплексные решения, часто включающие помимо собственно OLAP-системы СУБД , инструменты ETL (Extract Transform Load) и отчетности, в настоящее время используют гибридный подход к организации хранения активных данных системы, распределяя их тем или иным образом между РСУБД и специализированным хранилищем, а также между дисковыми структурами и кэшированием в оперативной памяти.
Так как эффективность такого решения зависит от конкретных подходов и алгоритмов, применяемых производителем для определения того, какие данные и где хранить , то поспешно делать выводы о изначально большей эффективности таких решений как класса без оценки конкретных особенностей рассматриваемой системы.
OLAP (англ. on-line analytical processing) – совокупность методов динамической обработки многомерных запросов в аналитических базах данных. Такие источники данных обычно имеют довольно большой объем, и в применяемых для их обработки средствах одним из наиболее важных требований является высокая скорость. В реляционных БД информация хранится в отдельных таблицах, которые хорошо нормализованы. Но сложные многотабличные запросы в них выполняются довольно медленно. Значительно лучшие показатели по скорости обработки в OLAP-системах достигаются за счет особенности структуры хранения данных. Вся информация четко организована, и применяются два типа хранилищ данных: измерения (содержат справочники, разделенные по категориям, например, точки продаж, клиенты, сотрудники, услуги и т.д.) и факты (характеризуют взаимодействие элементов различных измерений, например, 3 марта 2010 г. продавец A оказал услугу клиенту Б в магазине В на сумму Г денежных единиц). Для вычисления результатов в аналитическом кубе применяются меры. Меры представляют собой совокупности фактов, агрегированных по соответствующим выбранным измерениям и их элементам. Благодаря этим особенностям на сложные запросы с многомерными данными затрачивается гораздо меньшее время, чем в реляционных источниках.
Одним из основных вендоров OLAP-систем является корпорация Microsoft . Рассмотрим реализацию принципов OLAP на практических примерах создания аналитического куба в приложениях Microsoft SQL Server Business Intelligence Development Studio (BIDS) и Microsoft Office PerformancePoint Server Planning Business Modeler (PPS) и ознакомимся с возможностями визуального представления многомерных данных в виде графиков, диаграмм и таблиц.
Например, в BIDS необходимо создать OLAP-куб по данным о страховой компании, ее работниках, партнерах (клиентах) и точках продаж. Допустим предположение, что компания предоставляет один вид услуг, поэтому измерение услуг не понадобится.
Сначала определим измерения. С деятельности компании связаны следующие сущности (категории данных):
- Точки продаж
- Сотрудники
- Партнеры
Далее необходима одна таблица для хранения фактов (таблица фактов).
Информация в таблицы может вноситься вручную, но наиболее распространена загрузка данных с применением мастера импорта из различных источников.
На следующем рисунке представлена последовательность процесса создания и заполнения таблиц измерений и фактов вручную:
Рис.1. Таблицы измерений и фактов в аналитической БД. Последовательность создания
После создания многомерного источника данных в BIDS имеется возможность просмотреть его представление (Data Source View). В нашем примере получится схема, представленная на рисунке ниже.
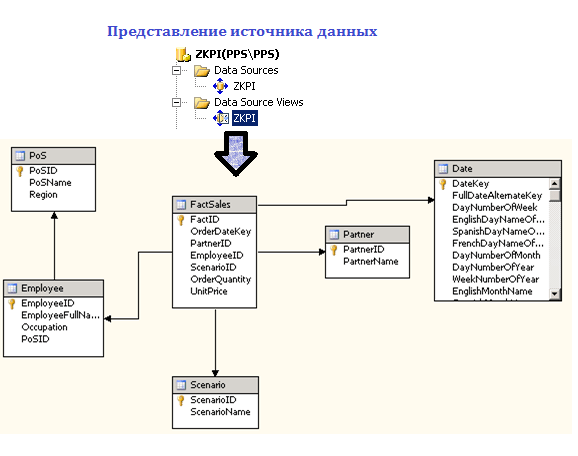
Рис.2. Представление источника данных (Data Source View) в Business Intellingence Development Studio (BIDS)
Как видим, таблица фактов связана с таблицами измерений посредством однозначного соответствия полей-идентификаторов (PartnerID, EmployeeID и т.д.).
Посмотрим на результат. На вкладке обозревателя куба, перетаскивая меры и измерения в поля итогов, строк, столбцов и фильтров, можем получить представление интересующих данных (к примеру, заключенные сделки по страховым договорам, заключенные определенным работником в 2005 году).
ведениеВ последнее время много написано про OLAP. Можно сказать, что наблюдается некоторый бум вокруг этих технологий. Правда, для нас этот бум несколько запоздал, но связано это, конечно, с общей ситуацией в стране.
Информационные системы масштаба предприятия, как правило, содержат приложения, предназначенные для комплексного многомерного анализа данных, их динамики, тенденций и т.п. Такой анализ в конечном итоге призван содействовать принятию решений. Нередко эти системы так и называются – системы поддержки принятия решений.
Системы поддержки принятия решений обычно обладают средствами предоставления пользователю агрегатных данных для различных выборок из исходного набора в удобном для восприятия и анализа виде. Как правило, такие агрегатные функции образуют многомерный (и, следовательно, нереляционный) набор данных (нередко называемый гиперкубом или метакубом), оси которого содержат параметры, а ячейки – зависящие от них агрегатные данные – причем храниться такие данные могут и в реляционных таблицах, но в данном случае мы говорим о логической организации данных, а не о физической реализации их хранения). Вдоль каждой оси данные могут быть организованы в виде иерархии, представляющей различные уровни их детализации. Благодаря такой модели данных пользователи могут формулировать сложные запросы, генерировать отчеты, получать подмножества данных.
Технология комплексного многомерного анализа данных получила название OLAP (On-Line Analytical Processing).
OLAP – это ключевой компонент организации хранилищ данных.
Концепция OLAP была описана в 1993 году Эдгаром Коддом, известным исследователем баз данных и автором реляционной модели данных (см. E.F. Codd, S.B. Codd, and C.T.Salley, Providing OLAP (on-line analytical processing) to user-analysts: An IT mandate. Technical report, 1993).
В 1995 году на основе требований, изложенных Коддом, был сформулирован так называемый тест FASMI (Fast Analysis of Shared Multidimensional Information – быстрый анализ разделяемой многомерной информации), включающий следующие требования к приложениям для многомерного анализа:
· предоставление пользователю результатов анализа за приемлемое время (обычно не более 5 с), пусть даже ценой менее детального анализа;
· возможность осуществления любого логического и статистического анализа, характерного для данного приложения, и его сохранения в доступном для конечного пользователя виде;
· многопользовательский доступ к данным с поддержкой соответствующих механизмов блокировок и средств авторизованного доступа;
· многомерное концептуальное представление данных, включая полную поддержку для иерархий и множественных иерархий (это – ключевое требование OLAP);
· возможность обращаться к любой нужной информации независимо от ее объема и места хранения.
Следует отметить, что OLAP-функциональность может быть реализована различными способами, начиная с простейших средств анализа данных в офисных приложениях и заканчивая распределенными аналитическими системами, основанными на серверных продуктах. Пользователи могут легко рассматривать данные на многомерной структуре в применении к собственным задачам.
2. Что такое OLAP
OLAP – аббревиатура от английского On-Line Analytical Processing – это название не конкретного продукта, а целой технологии. По-русски удобнее всего называть OLAP оперативной аналитической обработкой. Хотя в некоторых изданиях аналитическую обработку называют и онлайновой, и интерактивной, однако прилагательное “оперативная” как нельзя более точно отражает смысл технологии OLAP.
Разработка руководителем решений по управлению попадает в разряд областей наиболее сложно поддающихся автоматизации. Однако сегодня имеется возможность оказать помощь управленцу в разработке решений и, самое главное, значительно ускорить сам процесс разработки решений, их отбора и принятия. Для этого можно использовать OLAP.
Рассмотрим, как обычно происходит процесс разработки решений.
Исторически сложилось так, что решения по автоматизации оперативной деятельности наиболее развиты. Речь идет о системах транзакционной обработки данных (OLTP), проще называемых оперативными системами. Эти системы обеспечивают регистрацию некоторых фактов, их непродолжительное хранение и сохранение в архивах. Основу таких систем обеспечивают системы управления реляционными базами данных (РСУБД). Традиционным подходом являются попытки использовать уже построенные оперативные системы для поддержки принятия решений. Обычно пытаются строить развитую систему запросов к оперативной системе и использовать полученные после интерпретации отчеты непосредственно для поддержки решений. Отчеты могут строиться на заказной базе, т.е. руководитель запрашивает отчет, и на регулярной, когда отчеты строятся по достижении некоторых событий или времени. Например, традиционный процесс поддержки принятия решений может выглядеть таким образом: руководитель идет к специалисту информационного отдела и делится с ним своим вопросом. Затем специалист информационного отдела строит запрос к оперативной системе, получает электронный отчет, интерпретирует его и затем доводит его до сведения руководящего персонала. Конечно, такая схема обеспечивает в какой-то мере поддержку принятия решений, но она имеет крайне низкую эффективность и огромное число недостатков. Ничтожное количество данных используется для поддержки критически важных решений. Есть и другие проблемы. Подобный процесс очень медленен, так как длителен сам процесс написания запросов и интерпретации электронного отчета. Он занимает многие дни, в то время, когда руководителю может быть необходимо принять решение прямо сейчас, немедленно. Если учесть, что руководителя после получения отчета может заинтересовать другой вопрос (скажем, уточняющий или требующий рассмотрения данных в другом разрезе), то этот медленный цикл должен повториться, а поскольку процесс анализа данных оперативных систем будет происходить итерационно, то времени тратится ещё больше. Другая проблема – проблема различных областей деятельности специалиста по информационным технологиям и руководителя, которые могут мыслить в разных категориях и, как следствие, – не понимать друг друга. Тогда потребуются дополнительные уточняющие итерации, а это снова время, которого всегда не хватает. Ещё одной важной проблемой является сложность отчетов для понимания. У руководителя нет времени выбирать интересующие цифры из отчёта, тем более что их может оказаться слишком много (вспомним огромные многостраничные отчеты, в которых реально используются несколько страниц, а остальные – на всякий случай). Отметим также, что работа по интерпретации ложится чаще всего на специалистов информационных отделов. То есть грамотный специалист отвлекается на рутинную и малоэффективную работу по рисованию диаграмм и т.п., что, естественно, не может благоприятно сказываться на его квалификации. Кроме того, не является секретом присутствие в цепочке интерпретации благожелателей, заинтересованных в преднамеренном искажении поступающей информации.
Вышеуказанные недостатки заставляют задуматься и об общей эффективности оперативной системы, и о затратах, связанных с ее существованием, так как оказывается, что затраты на создание оперативной системы не окупаются в должной степени эффективностью ее работы.
В действительности проблемы эти не являются следствием низкого качества оперативной системы или ее неудачной постройки. Корни проблем кроются в фундаментальном отличии той оперативной деятельности, которая автоматизируется оперативной системой, и деятельностью по разработке и принятию решений. Отличие это состоит в том, что данные оперативных систем являются просто записями о некоторых имевших место событиях, фактах, но никак не информацией в общем смысле этого слова. Информация – то, что снижает неопределенность в какой-либо области. И очень неплохо, если бы информация снижала неопределенность в области подготовки решений. По поводу непригодности для этой цели оперативных систем, построенных на РСУБД, в свое время высказался небезызвестный E.F. Codd, человек, стоявший в 70-е годы у истоков технологий систем управления реляционными БД: “Хотя системы управления реляционными БД доступны для пользователей, они никогда не считались средством, дающим мощные функции по синтезу, анализу и консолидации (функций, называемых многомерным анализом данных)”. Речь идет именно о синтезе информации, о том, чтобы превращать данные оперативных систем в информацию и даже в качественные оценки. OLAP позволяет выполнять такое превращение.
В основе OLAP лежит идея многомерной модели данных. Человеческое мышление многомерно по определению. Когда человек задает вопросы, он налагает ограничения, тем самым формулируя вопросы во многих измерениях, поэтому процесс анализа в многомерной модели весьма приближен к реальности человеческого мышления. По измерениям в многомерной модели откладывают факторы, влияющие на деятельность предприятия (например: время, продукты, отделения компании, географию и т.п.). Таким образом получают гиперкуб (конечно, название не очень удачно, поскольку под кубом обычно понимают фигуру с равными ребрами, что, в данном случае, далеко не так), который затем наполняется показателями деятельности предприятия (цены, продажи, план, прибыли, убытки и т.п.). Наполнение это может вестись как реальными данными оперативных систем, так и прогнозируемыми на основе исторических данных. Измерения гиперкуба могут носить сложный характер, быть иерархическими, между ними могут быть установлены отношения. В процессе анализа пользователь может менять точку зрения на данные (так называемая операция смены логического взгляда), тем самым просматривая данные в различных разрезах и разрешая конкретные задачи. Над кубами могут выполняться различные операции, включая прогнозирование и условное планирование (анализ типа “что, если”). Причем операции выполняются разом над кубами, т.е. произведение, например, даст в результате произведение-гиперкуб, каждая ячейка которого является произведением ячеек соответствующих гиперкубов-множителей. Естественно, возможно выполнение операций над гиперкубами, имеющими различное число измерений.
3. История создания OLAP-технологии
Идея обработки данных на многомерных массивах не является новой. Фактически она восходит к 1962 году, когда Ken Iverson опубликовал свою книгу “Язык программирования” (“A Programming Language”, APL). Первая практическая реализация APL состоялась в поздних шестидесятых компанией IBM. APL – это очень изящный, математически определённый язык с многомерными переменными и обрабатываемыми операциями. Он подразумевался как оригинальное мощное средство по работе с многомерными преобразованиями по сравнению с другими практическими языками программирования.
Однако идея долгое время не получала массового применения, поскольку не пришло еще время графических интерфейсов, печатающих устройств высокого качества, а отображение греческих символов требовало специальных экранов, клавиатур и печатающих устройств. Позднее английские слова иногда использовали для замены греческих операторов, однако борцы за чистоту APL пресекли попытки популяризации их любимого языка. APL также поглощал машинные ресурсы. В те дни его использование требовало больших затрат. Программы очень медленно выполнялись и, кроме того, сам их запуск обходился очень дорого. Требовалось много памяти, по тем временам просто шокирующие объемы (около 6 МБ).
Однако досада от этих первоначальных ошибок не убила идею. Она использовалась во многих деловых приложениях 70-х, 80-х годов. Многие из этих приложений имели черты современных систем аналитической обработки. Так, IBM разработала операционную систему для APL, названную VSPC, и некоторые люди считали ее идеальной средой для персонального использования, пока электронные таблицы не стали повсеместно распространены.
Но APL был слишком сложен в использовании, тем более что каждый раз появлялись несоответствия между самим языком и оборудованием, на котором делались попытки его реализации.
В 80-х годах APL стал доступен на персональных машинах, но не нашел рыночного применения. Альтернативой было программирование многомерных приложений с использованием массивов в других языках. Это было очень тяжелой задачей даже для профессиональных программистов, что вынуждало ждать следующего поколения многомерных программных продуктов.
В 1972 году несколько прикладных многомерных программных продуктов, ранее использовавшихся в учебных целях, нашли коммерческое применение: Express. Он в полностью переписанном виде остаётся и сейчас, однако оригинальные концепции 70-х годов перестали быть актуальными. Сегодня, в 90-х, Express является одной из наиболее популярных OLAP-технологий, и Oracle (r) будет продвигать его и дополнять новыми возможностями.
Больше многомерных продуктов появилось в 80-х годах. В начале десятилетия – продукт с названием Stratagem, позднее называемый Acumate (сегодня владельцем является Kenan Technologies), который еще продвигался до начала 90-х, но сегодня, в отличие от Express, практически не используется.
Comshare System W был многомерным продуктом другого стиля. Представленный в 1981 году, он был первым, где предполагалась большая ориентированность на конечного пользователя и на разработку финансовых приложений. Он привнёс много концепций, которые, правда, не были хорошо адаптированы, такие, как полностью непроцедурные правила, полноэкранный просмотр и редактирование многомерных данных, автоматическое перевычисление и пакетная интеграция с реляционными данными. Однако Comshare System W был достаточно тяжел для аппаратного обеспечения того времени по сравнению с другими продуктами и меньше использовался в будущем, продавался всё меньше, и в продукте не делалось никаких улучшений. Хотя он и сегодня доступен на UNIX, он не является клиент-серверным, что не способствует повышению его предложения на рынке аналитических продуктов. В поздних 80-х Comshare выпустил продукт для DOS, а позднее для Windows. Эти продукты назывались Commander Prism и использовали те же концепции, что и System W.
Другой творческий продукт поздних 80-х назывался Metaphor. Он предназначался для профессиональных маркетологов. Он также предложил много новых концепций, которые только сегодня начинают широко использоваться: клиент-серверные вычисления, использование многомерной модели на реляционных данных, объектно-ориентированная разработка приложений. Однако стандартное аппаратное обеспечение персональных машин тех дней не было способно работать с Metaphor и поставщики вынуждены были разрабатывать собственные стандарты на персональные машины и сети. Постепенно Metaphor стал работать удачно и на серийных персональных машинах, однако продукт был выполнен исключительно для OS/2 и имел свой собственный графический интерфейс пользователя.
Затем Metaphor заключил маркетинговый альянс с IBM, которой впоследствии и был поглощён. В середине 1994 года IBM решила интегрировать технологию Metaphor (переименованную в DIS) со своими будущими технологиями и тем самым прекратить финансирование отдельного направления, однако заказчики выразили своё неудовольствие и потребовали продолжить поддержку продукта. Поддержка была продолжена для оставшихся заказчиков, а IBM перевыпустила продукт под новым названием DIS, что, однако, не сделало его популярным. Но творческие, новаторские концепции Metaphor не были забыты и видны сегодня во многих продуктах.
В середине 80-х родился термин EIS (Executive Information System – информационная система руководителя). Первым продуктом, ясно продемонстрировавшим это направление, был Pilot’s Command Center. Это был продукт, который позволял выполнять совместные вычисления, то, что мы называем сегодня клиент-серверными вычислениями. Поскольку мощность персональных компьютеров 80-х годов была ограничена, продукт был очень “сервероцентричен”, однако этот принцип и сегодня очень популярен. Pilot недолго продавал Command Center, но предложил много концепций, которые можно узнать в сегодняшних OLAP-продуктах, включая автоматическую поддержку временных промежутков, многомерные клиент-серверные вычисления и упрощённое управление процессом анализа (мышь, чувствительные экраны и т.п.). Некоторые из этих концепций были повторно применены позднее в Pilot Analysis Server.
В конце 80-х электронные таблицы были доминирующими на рынке инструментов, предоставляющих анализ конечным пользователям. Первая многомерная электронная таблица была представлена продуктом Compete. Он продвигался на рынок как очень дорогой продукт для специалистов, но поставщики не обеспечили возможность захвата рынка этим продуктом, и компания Computer Associates приобрела права на него вместе с другими продуктами, включая Supercalc и 20/20. Основным эффектом от приобретения CA Compete было резкое снижение цены на него и снятие защиты от копирования, что, естественно, способствовало его распространению. Однако он не был удачным. Compete положен в основу Supercalc 5, но многомерный аспект его не продвигается. Старый Compete всё ещё иногда используют в связи с тем, что в свое время в него были вложены немалые средства.
Компания Lotus была следующей, кто попытался войти на рынок многомерных электронных таблиц с продуктом Improv, который запускается на NeXT машине. Это гарантировало, как минимум, что продажи 1-2-3 не снизятся, но когда тот со временем был выпущен под Windows, Excel уже имел большую долю рынка, что не позволило Lotus внести какие-либо изменения в распределение рынка. Lotus, подобно CA с Compete, переместила Improv в нижнюю часть рынка, однако и это не стало условием удачного продвижения на рынке, и новые разработки в этой области не получили продолжения. Оказалось, что пользователи персональных компьютеров предпочли электронные таблицы 1-2-3 и не интересуются новыми многомерными возможностями, если они не полностью совместимы с их старыми таблицами. Так же концепции маленьких, настольных электронных таблиц, предлагаемых как персональные приложения, в действительности не оказались удобными и не прижились в настоящем деловом мире. Microsoft (r) пошла по этому пути, добавив PivotTables (в русской редакции это называется “сводные таблицы”) к Excel. Хотя немногие пользователи Excel получили выгоду от использования этой возможности, это, вероятно, единственный факт широкого использования в мире возможностей многомерного анализа просто потому, что в мире очень много пользователей Excel.
4. OLAP, ROLAP, MOLAP…
Общеизвестно, что когда Кодд опубликовал в 1985 году свои правила построения реляционных СУБД, они вызвали бурную реакцию и впоследствии сильно отразились вообще на индустрии СУБД. Однако мало кто знает, что в 1993 году Кодд опубликовал труд под названием “OLAP для пользователей-аналитиков: каким он должен быть”. В нем он изложил основные концепции оперативной аналитической обработки и определил 12 правил, которым должны удовлетворять продукты, предоставляющие возможность выполнения оперативной аналитической обработки.
Вот эти правила (текст оригинала сохранен по возможности):
1. Концептуальное многомерное представление. Пользователь-аналитик видит мир предприятия многомерным по своей природе. Соответственно и OLAP-модель должна быть многомерной в своей основе. Многомерная концептуальная схема или пользовательское представление облегчают моделирование и анализ так же, впрочем, как и вычисления.
2. Прозрачность. Вне зависимости от того, является OLAP-продукт частью средств пользователя или нет, этот факт должен быть прозрачен для пользователя. Если OLAP предоставляется клиент-серверными вычислениями, то этот факт также, по возможности, должен быть незаметен для пользователя. OLAP должен предоставляться в контексте истинно открытой архитектуры, позволяя пользователю, где бы он ни находился, связываться при помощи аналитического инструмента с сервером. В дополнение прозрачность должна достигаться и при взаимодействии аналитического инструмента с гомогенной и гетерогенной средами БД.
3. Доступность. Пользователь-аналитик OLAP должен иметь возможность выполнять анализ, базирующийся на общей концептуальной схеме, содержащей данные всего предприятия в реляционной БД, также как и данные из старых наследуемых БД, на общих методах доступа и на общей аналитической модели. Это значит, что OLAP должен предоставлять свою собственную логическую схему для доступа в гетерогенной среде БД и выполнять соответствующие преобразования для предоставления данных пользователю. Более того, необходимо заранее позаботиться о том, где и как, и какие типы физической организации данных действительно будут использоваться. OLAP-система должна выполнять доступ только к действительно требующимся данным, а не применять общий принцип “кухонной воронки”, который влечет ненужный ввод.
4. Постоянная производительность при разработке отчетов. Если число измерений или объем базы данных увеличиваются, пользователь-аналитик не должен чувствовать какой-либо существенной деградации в производительности. Постоянная производительность является критичной при поддержке для конечного пользователя легкости в использовании и ограничения сложности OLAP. Если пользователь-аналитик будет испытывать существенные различия в производительности в соответствии с числом измерений, тогда он будет стремиться компенсировать эти различия стратегией разработки, что вызовет представление данных другими путями, но не теми, которыми действительно нужно представить данные. Затраты времени на обход системы для компенсации ее неадекватности – это не то, для чего аналитические продукты предназначены.
5. Клиент-серверная архитектура. Большинство данных, которые сегодня требуется подвергать оперативной аналитической обработке, содержатся на мэйнфреймах с доступом через ПК. Это означает, следовательно, что OLAP-продукты должны быть способны работать в среде клиент-сервер. С этой точки зрения является необходимым, чтобы серверный компонент аналитического инструмента был существенно “интеллектуальным”, чтобы различные клиенты могли присоединяться к серверу с минимальными затруднениями и интеграционным программированием. “Интеллектуальный” сервер должен быть способен выполнять отображение и консолидацию между несоответствующими логическими и физическими схемами баз данных. Это обеспечит прозрачность и построение общей концептуальной, логической и физической схемы.
6. Общая многомерность. Каждое измерение должно применяться безотносительно своей структуры и операционных способностей. Дополнительные операционные способности могут предоставляться выбранным измерениям, и, поскольку измерения симметричны, отдельно взятая функция может быть предоставлена любому измерению. Базовые структуры данных, формулы и форматы отчетов не должны смещаться в сторону какого-либо измерения.
7. Динамическое управление разреженными матрицами. Физическая схема OLAP-инструмента должна полностью адаптироваться к специфической аналитической модели для оптимального управления разреженными матрицами. Для любой взятой разреженной матрицы существует одна и только одна оптимальная физическая схема. Эта схема предоставляет максимальную эффективность по памяти и операбельность матрицы, если, конечно, весь набор данных не помещается в памяти. Базовые физические данные OLAP-инструмента должны конфигурироваться к любому подмножеству измерений, в любом порядке, для практических операций с большими аналитическими моделями. Физические методы доступа также должны динамически меняться и содержать различные типы механизмов, таких как: непосредственные вычисления, B-деревья и производные, хеширование, возможность комбинировать эти механизмы при необходимости. Разреженность (измеряется в процентном отношении пустых ячеек ко всем возможным) – это одна из характеристик распространения данных. Невозможность регулировать разреженность может сделать эффективность операций недостижимой. Если OLAP-инструмент не может контролировать и регулировать распространение значений анализируемых данных, модель, претендующая на практичность, базирующаяся на многих путях консолидации и измерениях, в действительности может оказаться ненужной и безнадежной.
8. Многопользовательская поддержка. Часто несколько пользователей-аналитиков испытывают потребность работать совместно с одной аналитической моделью или создавать различные модели из единых данных. Следовательно, OLAP-инструмент должен предоставлять возможности совместного доступа (запроса и дополнения), целостности и безопасности.
9. Неограниченные перекрестные операции. Различные уровни свертки и пути консолидации, вследствие их иерархической природы, представляют зависимые отношения в OLAP-модели или приложении. Следовательно, сам инструмент должен подразумевать соответствующие вычисления и не требовать от пользователя-аналитика вновь определять эти вычисления и операции. Вычисления, не следующие из этих наследуемых отношений, требуют определения различными формулами в соответствии с некоторым применяющимся языком. Такой язык может позволять вычисления и манипуляцию с данными любых размерностей и не ограничивать отношения между ячейками данных, не обращать внимания на количество общих атрибутов данных конкретных ячеек.
10. Интуитивная манипуляция данными. Переориентация путей консолидации, детализация, укрупнение и другие манипуляции, регламентируемые путями консолидации, должны применяться через отдельное воздействие на ячейки аналитической модели, а также не должны требовать использования системы меню или иных множественных действий с пользовательским интерфейсом. Взгляд пользователя-аналитика на измерения, определенный в аналитической модели, должен содержать всю необходимую информацию, чтобы выполнять вышеуказанные действия.
11. Гибкие возможности получения отчетов. Анализ и представление данных являются простыми, когда строки, столбцы и ячейки данных, которые будут визуально сравниваться между собой, будут находиться вблизи друг друга или по некоторой логической функции, имеющей место на предприятии. Средства формирования отчетов должны представлять синтезируемые данные или информацию, следующую из модели данных в ее любой возможной ориентации. Это означает, что строки, столбцы или страницы должны показывать одновременно от 0 до N измерений, где N – число измерений всей аналитической модели. В дополнение каждое измерение содержимого, показанное в одной записи, колонке или странице, должно также быть способно показать любое подмножество элементов (значений), содержащихся в измерении, в любом порядке.
12. Неограниченная размерность и число уровней агрегации. Исследование о возможном числе необходимых измерений, требующихся в аналитической модели, показало, что одновременно может использоваться до 19 измерений. Отсюда вытекает настоятельная рекомендация, чтобы аналитический инструмент был способен предоставить хотя бы 15 измерений одновременно и предпочтительно 20. Более того, каждое из общих измерений не должно быть ограничено по числу определяемых пользователем-аналитиком уровней агрегации и путей консолидации.
Фактически сегодня разработчики OLAP-продуктов следуют этим правилам или, по крайней мере, стремятся им следовать. Эти правила можно считать теоретическим базисом оперативной аналитической обработки, с ними трудно спорить. Впоследствии было выведено множество следствий из 12 правил, которые мы, однако, не будем приводить, дабы излишне не усложнять повествование.
Остановимся несколько подробнее на том, как отличаются OLAP-продукты по своей физической реализации.
Как уже отмечалось выше, в основе OLAP лежит идея обработки данных на многомерных структурах. Когда мы говорим OLAP, мы подразумеваем, что логически структура данных аналитического продукта многомерна. Другое дело, как именно это реализовано. Различают два основных вида аналитической обработки, к которым относят те или иные продукты.
MOLAP. Собственно многомерная (multidimensional) OLAP. В основе продукта лежит нереляционная структура данных, обеспечивающая многомерное хранение, обработку и представление данных. Соответственно и базы данных называют многомерными. Продукты, относящиеся к этому классу, обычно имеют сервер многомерных баз данных. Данные в процессе анализа выбираются исключительно из многомерной структуры. Подобная структура является высокопроизводительной.
ROLAP. Реляционная (relational) OLAP. Как и подразумевается названием, многомерная структура в таких инструментах реализуется реляционными таблицами. А данные в процессе анализа, соответственно, выбираются из реляционной базы данных аналитическим инструментом.
Недостатки и преимущества каждого подхода, в общем-то, очевидны. Многомерная OLAP обеспечивает лучшую производительность, но структуры нельзя использовать для обработки больших объемов данных, поскольку большая размерность потребует больших аппаратных ресурсов, а вместе с тем разреженность гиперкубов может быть очень высокой и, следовательно, использование аппаратных мощностей не будет оправданным. Наоборот, реляционная OLAP обеспечивает обработку на больших массивах хранимых данных, так как возможно обеспечение более экономичного хранения, но, вместе с тем, значительно проигрывает в скорости работы многомерной. Подобные рассуждения привели к выделению нового класса аналитических инструментов – HOLAP. Это гибридная (hybrid) оперативная аналитическая обработка. Инструменты этого класса позволяют сочетать оба подхода – реляционного и многомерного. Доступ может вестись как к данным многомерных баз, так и к данным реляционных.
Есть еще один достаточно экзотический вид оперативной аналитической обработки – DOLAP. Это “настольный” (desktop) OLAP. Речь идет о такой аналитической обработке, где гиперкубы малы, размерность их небольшая, потребности скромны, и для такой аналитической обработки достаточно персональной машины на рабочем столе.
Оперативная аналитическая обработка позволяет значительно упростить и ускорить процесс подготовки и принятия решений руководящим персоналом. Оперативная аналитическая обработка служит цели превращения данных в информацию. Она принципиально отличается от традиционного процесса поддержки принятия решений, основанного, чаще всего, на рассмотрении структурированных отчетов. По аналогии, разница между структурированными отчетами и OLAP такая, как между ездой по городу на трамвае и на личном автомобиле. Когда вы едете на трамвае, он двигается по рельсам, что не позволяет хорошо рассмотреть отдаленные здания и тем более приблизиться к ним. Наоборот, езда на личном автомобиле дает полную свободу передвижения (естественно, следует соблюдать ПДД). Можно подъехать к любому зданию и добраться до тех мест, где трамваи не ходят.
Структурированные отчеты – это те рельсы, которые сдерживают свободу в подготовке решений. OLAP – автомобиль для эффективного движения по информационным магистралям.
Условия высокой конкуренции и растущей динамики внешней среды диктуют повышенные требования к системам управления предприятия. Развитие теории и практики управления сопровождались появлением новых методов, технологий и моделей, ориентированных на повышение эффективности деятельности. Методы и модели в свою очередь способствовали появлению аналитических систем. Востребованность аналитических систем в России – высокая. Наиболее интересны с точки зрения применения эти системы в финансовой сфере: банки, страховой бизнес, инвестиционные компании. Результаты работы аналитических систем необходимы в первую очередь людям, от решения которых зависит развитие компании: руководителям, экспертам, аналитикам. Аналитические системы позволяют решать задачи консолидации, отчетности, оптимизации и прогнозирования. До настоящего времени не сложилось окончательной классификации аналитических систем, как и нет общей системы определений в терминах, использующихся в данном направлении. Информационная структура предприятия может быть представлена последовательностью уровней, каждый из которых характеризуется своим способом обработки и управления информацией, и имеет свою функцию в процессе управления. Таким образом аналитические системы будут располагаться иерархически на разных уровнях этой инфраструктуры.
Уровень транзакционных систем
Уровень хранилищ данных
Уровень витрин данных
Уровень OLAP – систем
Уровень аналитических приложений
OLAP - системы - (OnLine Analytical Processing, аналитическая обработка в настоящем времени) - представляют собой технологию комплексного многомерного анализа данных. OLAP - системы применимы там, где есть задача анализа многофакторных данных. Являют собой эффективное средство анализа и генерации отчетов. Рассмотренные выше хранилища данных, витрины данных и OLAP - системы относятся к системам бизнес - интеллекта (Business Intelligence, BI).
Очень часто информационно-аналитические системы, создаваемые в расчете на непосредственное использование лицами, принимающими решения, оказываются чрезвычайно просты в применении, но жестко ограничены в функциональности. Такие статические системы называются в литературе Информационными системами руководителя (ИСР), или Executive Information Systems (EIS) . Они содержат в себе предопределенные множества запросов и, будучи достаточными для повседневного обзора, неспособны ответить на все вопросы к имеющимся данным, которые могут возникнуть при принятии решений. Результатом работы такой системы, как правило, являются многостраничные отчеты, после тщательного изучения которых у аналитика появляется новая серия вопросов. Однако каждый новый запрос, непредусмотренный при проектировании такой системы, должен быть сначала формально описан, закодирован программистом и только затем выполнен. Время ожидания в таком случае может составлять часы и дни, что не всегда приемлемо. Таким образом, внешняя простота статических СППР, за которую активно борется большинство заказчиков информационно-аналитических систем, оборачивается катастрофической потерей гибкости.
Динамические СППР, напротив, ориентированы на обработку нерегламентированных (ad hoc) запросов аналитиков к данным. Наиболее глубоко требования к таким системам рассмотрел E. F. Codd в статье , положившей начало концепции OLAP. Работа аналитиков с этими системами заключается в интерактивной последовательности формирования запросов и изучения их результатов.
Но динамические СППР могут действовать не только в области оперативной аналитической обработки (OLAP); поддержка принятия управленческих решений на основе накопленных данных может выполняться в трех базовых сферах .
Сфера детализированных данных. Это область действия большинства систем, нацеленных на поиск информации. В большинстве случаев реляционные СУБД отлично справляются с возникающими здесь задачами. Общепризнанным стандартом языка манипулирования реляционными данными является SQL. Информационно-поисковые системы, обеспечивающие интерфейс конечного пользователя в задачах поиска детализированной информации, могут использоваться в качестве надстроек как над отдельными базами данных транзакционных систем, так и над общим хранилищем данных.
Сфера агрегированных показателей. Комплексный взгляд на собранную в хранилище данных информацию, ее обобщение и агрегация, гиперкубическое представление и многомерный анализ являются задачами систем оперативной аналитической обработки данных (OLAP) . Здесь можно или ориентироваться на специальные многомерные СУБД , или оставаться в рамках реляционных технологий. Во втором случае заранее агрегированные данные могут собираться в БД звездообразного вида, либо агрегация информации может производиться на лету в процессе сканирования детализированных таблиц реляционной БД.
Сфера закономерностей. Интеллектуальная обработка производится методами интеллектуального анализа данных (ИАД, Data Mining) , главными задачами которых являются поиск функциональных и логических закономерностей в накопленной информации, построение моделей и правил, которые объясняют найденные аномалии и/или прогнозируют развитие некоторых процессов.
Оперативная аналитическая обработка данных
В основе концепции OLAP лежит принцип многомерного представления данных. В 1993 году в статье E. F. Codd рассмотрел недостатки реляционной модели, в первую очередь указав на невозможность "объединять, просматривать и анализировать данные с точки зрения множественности измерений, то есть самым понятным для корпоративных аналитиков способом", и определил общие требования к системам OLAP, расширяющим функциональность реляционных СУБД и включающим многомерный анализ как одну из своих характеристик.
Классификация продуктов OLAP по способу представления данных.
В настоящее время на рынке присутствует большое количество продуктов, которые в той или иной степени обеспечивают функциональность OLAP. Около 30 наиболее известных перечислены в списке обзорного Web-сервера http://www.olapreport.com/. Обеспечивая многомерное концептуальное представление со стороны пользовательского интерфейса к исходной базе данных, все продукты OLAP делятся на три класса по типу исходной БД.
Самые первые системы оперативной аналитической обработки (например, Essbase компании Arbor Software , Oracle Express Server компании Oracle ) относились к классу MOLAP, то есть могли работать только со своими собственными многомерными базами данных. Они основываются на патентованных технологиях для многомерных СУБД и являются наиболее дорогими. Эти системы обеспечивают полный цикл OLAP-обработки. Они либо включают в себя, помимо серверного компонента, собственный интегрированный клиентский интерфейс, либо используют для связи с пользователем внешние программы работы с электронными таблицами. Для обслуживания таких систем требуется специальный штат сотрудников, занимающихся установкой, сопровождением системы, формированием представлений данных для конечных пользователей.
Системы оперативной аналитической обработки реляционных данных (ROLAP) позволяют представлять данные, хранимые в реляционной базе, в многомерной форме , обеспечивая преобразование информации в многомерную модель через промежуточный слой метаданных. ROLAP-системы хорошо приспособлены для работы с крупными хранилищами. Подобно системам MOLAP, они требуют значительных затрат на обслуживание специалистами по информационным технологиям и предусматривают многопользовательский режим работы.
Наконец, гибридные системы (Hybrid OLAP, HOLAP) разработаны с целью совмещения достоинств и минимизации недостатков, присущих предыдущим классам. К этому классу относится Media/MR компании Speedware . По утверждению разработчиков, он объединяет аналитическую гибкость и скорость ответа MOLAP с постоянным доступом к реальным данным, свойственным ROLAP.
Многомерный OLAP (MOLAP)
В специализированных СУБД, основанных на многомерном представлении данных, данные организованы не в форме реляционных таблиц, а в виде упорядоченных многомерных массивов:
1) гиперкубов (все хранимые в БД ячейки должны иметь одинаковую мерность, то есть находиться в максимально полном базисе измерений) или
2) поликубов (каждая переменная хранится с собственным набором измерений, и все связанные с этим сложности обработки перекладываются на внутренние механизмы системы).
Использование многомерных БД в системах оперативной аналитической обработки имеет следующие достоинства.
В случае использования многомерных СУБД поиск и выборка данных осуществляется значительно быстрее, чем при многомерном концептуальном взгляде на реляционную базу данных, так как многомерная база данных денормализована, содержит заранее агрегированные показатели и обеспечивает оптимизированный доступ к запрашиваемым ячейкам.
Многомерные СУБД легко справляются с задачами включения в информационную модель разнообразных встроенных функций, тогда как объективно существующие ограничения языка SQL делают выполнение этих задач на основе реляционных СУБД достаточно сложным, а иногда и невозможным.
С другой стороны, имеются существенные ограничения.
Многомерные СУБД не позволяют работать с большими базами данных. К тому же за счет денормализации и предварительно выполненной агрегации объем данных в многомерной базе, как правило, соответствует (по оценке Кодда ) в 2.5-100 раз меньшему объему исходных детализированных данных.
Многомерные СУБД по сравнению с реляционными очень неэффективно используют внешнюю память. В подавляющем большинстве случаев информационный гиперкуб является сильно разреженным, а поскольку данные хранятся в упорядоченном виде, неопределенные значения удаётся удалить только за счет выбора оптимального порядка сортировки, позволяющего организовать данные в максимально большие непрерывные группы. Но даже в этом случае проблема решается только частично. Кроме того, оптимальный с точки зрения хранения разреженных данных порядок сортировки скорее всего не будет совпадать с порядком, который чаще всего используется в запросах. Поэтому в реальных системах приходится искать компромисс между быстродействием и избыточностью дискового пространства, занятого базой данных.
Следовательно, использование многомерных СУБД оправдано только при следующих условиях.
Объем исходных данных для анализа не слишком велик (не более нескольких гигабайт), то есть уровень агрегации данных достаточно высок.
Набор информационных измерений стабилен (поскольку любое изменение в их структуре почти всегда требует полной перестройки гиперкуба).
Время ответа системы на нерегламентированные запросы является наиболее критичным параметром.
Требуется широкое использование сложных встроенных функций для выполнения кроссмерных вычислений над ячейками гиперкуба, в том числе возможность написания пользовательских функций.
Реляционный OLAP (ROLAP)
Непосредственное использование реляционных БД в системах оперативной аналитической обработки имеет следующие достоинства.
В большинстве случаев корпоративные хранилища данных реализуются средствами реляционных СУБД, и инструменты ROLAP позволяют производить анализ непосредственно над ними. При этом размер хранилища не является таким критичным параметром, как в случае MOLAP.
В случае переменной размерности задачи, когда изменения в структуру измерений приходится вносить достаточно часто, ROLAP системы с динамическим представлением размерности являются оптимальным решением, так как в них такие модификации не требуют физической реорганизации БД.
Реляционные СУБД обеспечивают значительно более высокий уровень защиты данных и хорошие возможности разграничения прав доступа.
Главный недостаток ROLAP по сравнению с многомерными СУБД - меньшая производительность. Для обеспечения производительности, сравнимой с MOLAP, реляционные системы требуют тщательной проработки схемы базы данных и настройки индексов, то есть больших усилий со стороны администраторов БД. Только при использовании звездообразных схем производительность хорошо настроенных реляционных систем может быть приближена к производительности систем на основе многомерных баз данных.
Введение
В наше время без систем управления базами данных не обходится практически ни одна организация, особенно среди тех, которые традиционно ориентированы на взаимодействие с клиентами. Банки, страховые компании, авиа- и прочие транспортные компании, сети супермаркетов, телекоммуникационные и маркетинговые фирмы, организации, занятые в сфере услуг и другие - все они собирают и хранят в своих базах гигабайты данных о клиентах, продуктах и сервисах. Ценность подобных сведений несомненна. Такие базы данных называют операционными или транзакционными, поскольку они характеризуются огромным количеством небольших транзакций, или операций записи-чтения. Компьютерные системы, осуществляющие учет операций и собственно доступ к базам транзакций, принято называть системами оперативной обработки транзакций (OLTP - On-Line Transactional Processing) или учетными системами.
Учетные системы настраиваются и оптимизируются для выполнения максимального количества транзакций за короткие промежутки времени. Обычно отдельные операции очень малы и не связаны друг с другом. Однако каждую запись данных, характеризующую взаимодействие с клиентом (звонок в службу поддержки, кассовую операцию, заказ по каталогу, посещение Web-сайта компании и т.п.) можно использовать для получения качественно новой информации, а именно для создания отчетов и анализа деятельности фирмы.
Набор аналитических функций в учетных системах обычно весьма ограничен. Схемы, используемые в OLTP-приложениях, осложняют создание даже простых отчетов, так как данные чаще всего распределены по множеству таблиц, и для их агрегирования необходимо выполнять сложные операции объединения. Как правило, попытки создания комплексных отчетов требуют больших вычислительных мощностей и приводят к потере производительности.
Кроме того, в учетных системах хранятся постоянно изменяющиеся данные. По мере сбора транзакций суммарные значения меняются очень быстро, поэтому два анализа, проведенные с интервалом в несколько минут, могут дать разные результаты. Чаще всего, анализ выполнятся по окончании отчетного периода, иначе картина может оказаться искаженной. Кроме того, необходимые для анализа данные могут храниться в нескольких системах.
Некоторые виды анализа требуют таких структурных изменений, которые недопустимы в текущей оперативной среде. Например, нужно выяснить, что произойдет, если у компании появятся новые продукты. На живой базе такое исследование провести нельзя. Следовательно, эффективный анализ редко удается выполнить непосредственно в учетной системе.
Системы поддержки принятия решений обычно обладают средствами предоставления пользователю агрегатных данных для различных выборок из исходного набора в удобном для восприятия и анализа виде. Как правило, такие агрегатные функции образуют многомерный (и, следовательно, нереляционный) набор данных (нередко называемый гиперкубом или метакубом), оси которого содержат параметры, а ячейки - зависящие от них агрегатные данные - причем храниться такие данные могут и в реляционных таблицах. Вдоль каждой оси данные могут быть организованы в виде иерархии, представляющей различные уровни их детализации. Благодаря такой модели данных пользователи могут формулировать сложные запросы, генерировать отчеты, получать подмножества данных.
Именно это и обусловило интерес к системам поддержки принятия решений, ставших основной сферой применения OLAP (On-Line Analytical Processing, оперативная аналитическая обработка, оперативный анализ данных), превращающей “руду” OLTP-систем в готовое “изделие”, которое руководители и аналитики могут непосредственно использовать. Этот метод позволяет аналитикам, менеджерам и руководителям "проникнуть в суть" накопленных данных за счет быстрого и согласованного доступа к широкому спектру представлений информации.
Целью курсовой работы является рассмотрение технологии OLAP.
многомерный аналитический обработка данный
Основная часть
1 Основные сведения об OLAP
В основе концепции OLAP лежит принцип многомерного представления данных. В 1993 году термин OLAPввел Эдгар Кодд. Рассмотрев недостатки реляционной модели, он в первую очередь указал на невозможность «объединять, просматривать и анализировать данные с точки зрения множественности измерений, то есть самым понятным для корпоративных аналитиков способом», и определил общие требования к системам OLAP, расширяющим функциональность реляционных СУБД и включающим многомерный анализ как одну из своих характеристик .
В большом числе публикаций аббревиатурой OLAP обозначается не только многомерный взгляд на данные, но и хранение самих данных в многомерной БД. Вообще говоря, это неверно, поскольку сам Кодд отмечает, что "Реляционные БД были, есть и будут наиболее подходящей технологией для хранения корпоративных данных. Необходимость существует не в новой технологии БД, а, скорее, в средствах анализа, дополняющих функции существующих СУБД и достаточно гибких, чтобы предусмотреть и автоматизировать разные виды интеллектуального анализа, присущие OLAP". Такая путаница приводит к противопоставлениям наподобие "OLAP или ROLAP", что не совсем корректно, поскольку ROLAP (реляционный OLAP) на концептуальном уровне поддерживает всю определенную термином OLAP функциональность. Более предпочтительным кажется использование для OLAP на основе многомерных СУБД специального термина MOLAP. По Кодду, многомерное концептуальное представление (multi-dimensional conceptual view) представляет собой множественную перспективу, состоящую из нескольких независимых измерений, вдоль которых могут быть проанализированы определенные совокупности данных. Одновременный анализ по нескольким измерениям определяется как многомерный анализ. Каждое измерение включает направления консолидации данных, состоящие из серии последовательных уровней обобщения, где каждый вышестоящий уровень соответствует большей степени агрегации данных по соответствующему измерению. Так, измерение.
Исполнитель может определяться направлением консолидации, состоящим из уровней обобщения "предприятие - подразделение - отдел - служащий". Измерение Время может даже включать два направления консолидации - "год - квартал - месяц - день" и "неделя - день", поскольку счет времени по месяцам и по неделям несовместим. В этом случае становится возможным произвольный выбор желаемого уровня детализации информации по каждому из измерений. Операция спуска (drilling down) соответствует движению от высших ступеней консолидации к низшим; напротив, операция подъема (rolling up) означает движение от низших уровней к высшим.
Кодд определил 12 правил, которым должен удовлетворять программный продукт класса OLAP .
1.2 Требования к средствам оперативной аналитической обработки
Многомерное концептуальное представление данных (Multi Dimensional Conceptual View). Концептуальное представление модели данных в продукте OLAP должно быть многомерным по своей природе, то есть позволять аналитикам выполнять интуитивные операции "анализа вдоль и поперек" ("slice and dice"), вращения (rotate) и размещения (pivot) направлений консолидации. Прозрачность (Transparency). Пользователь не должен знать о том, какие конкретные средства используются для хранения и обработки данных, как данные организованы и откуда берутся.
Доступность (Accessibility). Аналитик должен иметь возможность выполнять анализ в рамках общей концептуальной схемы, но при этом данные могут оставаться под управлением оставшихся от старого наследства СУБД, будучи при этом привязанными к общей аналитической модели. То есть инструментарий OLAP должен накладывать свою логическую схему на физические массивы данных, выполняя все преобразования, требующиеся для обеспечения единого, согласованного и целостного взгляда пользователя на информацию.
Устойчиваяпроизводительность(Consistent Reporting Performance). С увеличением числа измерений и размеров базы данных аналитики не должны столкнуться с каким бы то ни было уменьшением производительности. Устойчивая производительность необходима для поддержания простоты использования и свободы от усложнений, которые требуются для доведения OLAP до конечного пользователя.
Клиент - серверная архитектура (Client-Server Architecture). Большая часть данных, требующих оперативной аналитической обработки, хранится в мэйнфреймовых системах, а извлекается с персональных компьютеров. Поэтому одним из требований является способность продуктов OLAP работать в среде клиент-сервер. Главной идеей здесь является то, что серверный компонент инструмента OLAP должен быть достаточно интеллектуальным и обладать способностью строить общую концептуальную схему на основе обобщения и консолидации различных логических и физических схем корпоративных баз данных для обеспечения эффекта прозрачности.
Равноправие измерений (Generic Dimensionality). Все измерения данных должны быть равноправны. Дополнительные характеристики могут быть предоставлены отдельным измерениям, но поскольку все они симметричны, данная дополнительная функциональность может быть предоставлена любому измерению. Базовая структура данных, формулы и форматы отчетов не должны опираться на какое-то одно измерение.
Динамическая обработка разреженных матриц (Dynamic Sparse Matrix Handling). Инструмент OLAP должен обеспечивать оптимальную обработку разреженных матриц. Скорость доступа должна сохраняться вне зависимости от расположения ячеек данных и быть постоянной величиной для моделей, имеющих разное число измерений и различную разреженность данных.
Поддержка многопользовательского режима (Multi-User Support). Зачастую несколько аналитиков имеют необходимость работать одновременно с одной аналитической моделью или создавать различные модели на основе одних корпоративных данных. Инструмент OLAP должен предоставлять им конкурентный доступ, обеспечивать целостность и защиту данных.
Неограниченная поддержка кроссмерных операций (Unrestricted Cross-dimensional Operations). Вычисления и манипуляция данными по любому числу измерений не должны запрещать или ограничивать любые отношения между ячейками данных. Преобразования, требующие произвольного определения, должны задаваться на функционально полном формульном языке.
Интуитивное манипулирование данными (Intuitive Data Manipulation). Переориентация направлений консолидации, детализация данных в колонках и строках, агрегация и другие манипуляции, свойственные структуре иерархии направлений консолидации, должны выполняться в максимально удобном, естественном и комфортном пользовательском интерфейсе .
Гибкий механизм генерации отчетов (Flexible Reporting). Должны поддерживаться различные способы визуализации данных, то есть отчеты должны представляться в любой возможной ориентации.
Неограниченное количество измерений и уровней агрегации (Unlimited Dimensions and Aggregation Levels). Настоятельно рекомендуется допущение в каждом серьезном OLAP инструменте как минимум пятнадцати, а лучше двадцати, измерений в аналитической модели.
2 Компоненты OLAP-систем
2.1 Сервер. Клиент. Интернет
OLAP позволяет выполнять быстрый и эффективный анализ над большими объемами данных. Данные хранятся в многомерном виде, что наиболее близко отражает естественное состояние реальных бизнес-данных. Кроме того, OLAP предоставляет пользователям возможность быстрее и проще получать сводные данные. С его помощью они могут при необходимости углубляться (drill down) в содержимое этих данных для получения более детализированной информации.
OLAP-система состоит из множества компонент. На самом высоком уровне представления система включает в себя источник данных, OLAP-сервер и клиента. Источник данных представляет собой источник, из которого берутся данные для анализа. Данные из источника переносятся или копируются на OLAP-сервер, где они систематизируются и подготавливаются для более быстрого впоследствии формирования ответов на запросы. Клиент - это пользовательский интерфейс к OLAP-серверу. В этом разделе статьи описываются функции каждой компоненты и значение всей системы в целом. Источники. Источником в OLAP-системах является сервер, поставляющий данные для анализа. В зависимости от области использования OLAP-продукта источником может служить Хранилище данных, наследуемая база данных, содержащая общие данные, набор таблиц, объединяющих финансовые данные или любая комбинация перечисленного. Способность OLAP-продукта работать с данными из различных источников очень важна. Требование единого формата или единой базы, в которых бы хранились все исходные данные, не подходит администраторам баз данных. Кроме того, такой подход уменьшает гибкость и мощность OLAP-продукта. Администраторы и пользователи полагают, что OLAP-продукты, обеспечивающие извлечение данных не только из различных, но и из множества источников, оказываются более гибкими и полезными, чем те, что имеют более жесткие требования.
Сервер. Прикладной частью OLAP-системы является OLAP-сервер. Эта составляющая выполняет всю работу (в зависимости от модели системы), и хранит в себе всю информацию, к которой обеспечивается активный доступ. Архитектурой сервера управляют различные концепции. В частности, основной функциональной характеристикой OLAP-продукта является использование для хранения данных многомерной (ММБД, MDDB) либо реляционной (РДБ, RDB) базы данных. Агрегированные/Предварительно агрегированные данные
Быстрая реализация запросов является императивом для OLAP. Это один из базовых принципов OLAP - способность интуитивно манипулировать данными требует быстрого извлечения информации. В целом, чем больше вычислений необходимо произвести, чтобы получить фрагмент информации, тем медленнее происходит отклик. Поэтому, чтобы сохранить маленькое время реализации запросов, фрагменты информации, обращение к которым обычно происходит наиболее часто, но которые при этом требуют вычисления, подвергаются предварительной агрегации. То есть они подсчитываются и затем хранятся в базе данных в качестве новых данных. В качестве примера типа данных, который допустимо рассчитать заранее, можно привести сводные данные - например, показатели продаж по месяцам, кварталам или годам, для которых действительно введенными данными являются ежедневные показатели .
Различные поставщики придерживаются различных методов отбора параметров, требующих предварительной агрегации и числа предварительно вычисляемых величин. Подход к агрегации влияет одновременно и на базу данных и на время реализации запросов. Если вычисляется больше величин, вероятность того, что пользователь запросит уже вычисленную величину, возрастает, и поэтому время отклика сократиться, так как не придется запрашивать изначальную величину для вычисления. Однако, если вычислить все возможные величины - это не лучшее решение - в таком случае существенно возрастает размер базы данных, что сделает ее неуправляемой, да и время агрегации будет слишком большим. К тому же, когда в базу данных добавляются числовые значения, или если они изменяются, информация эта должна отражаться на предварительно вычисленных величинах, зависящих от новых данных. Таким образом, и обновление базы может также занять много времени в случае большого числа предварительно вычисляемых величин. Поскольку обычно во время агрегации база данных работает автономно, желательно, чтобы время агрегации было не слишком длительным.
Клиент. Клиент - это как раз то, что используется для представления и манипуляций с данными в базе данных. Клиент может быть и достаточно несложным - в виде таблицы, включающей в себя такие возможности OLAP, как, например, вращение данных (пивотинг) и углубление в данные (дриллинг), и представлять собой специализированное, но такое же простое средство просмотра отчетов или быть таким же мощным инструментом, как созданное на заказ приложение, спроектированное для сложных манипуляций с данными. Интернет является новой формой клиента. Кроме того, он несет на себе печать новых технологий; множество интернет-решений существенно отличаются по своим возможностям в целом и в качестве OLAP-решения - в частности. В данном разделе обсуждаются различные функциональные свойства каждого типа клиентов.
Несмотря на то, что сервер - это как бы "хребет" OLAP-решения, клиент не менее важен. Сервер может обеспечить прочный фундамент для облегчения манипуляций с данными, но если клиент сложен или малофункционален, пользователь не сможет воспользоваться всеми преимуществами мощного сервера. Клиент настолько важен, что множество поставщиков сосредотачивают свои усилия исключительно на разработке клиента. Все, что включается в состав этих приложений, представляет собой стандартный взгляд на интерфейс, заранее определенные функции и структуру, а также быстрые решения для более или менее стандартных ситуаций. Например, популярны финансовые пакеты. Заранее созданные финансовые приложения позволят специалистам использовать привычные финансовые инструменты без необходимости проектировать структуру базы данных или общепринятые формы и отчеты. Инструмент запросов/Генератор отчетов. Инструмент запросов или генератор отчетов предлагает простой доступ к OLAP-данным. Они имеют простой в использовании графический интерфейс и позволяют пользователям создавать отчеты перемещением объектов в отчет методом "drag and drop". Тогда как традиционный генератор отчетов предоставляет пользователю возможность быстро выпускать форматированные отчеты, генераторы отчетов, поддерживающие OLAP, формируют актуальные отчеты. Конечный продукт представляет собой отчет, имеющий возможности углубления в данные до уровня подробностей, вращения (пивотинг) отчетов, поддержки иерархий и др.. Add-Ins (дополнения) электронных таблиц.
Сегодня во многих направлениях бизнеса с помощью электронных таблиц производятся различные формы анализа корпоративных данных. В каком-то смысле это идеальное средство создания отчетов и просмотра данных. Аналитик может создавать макросы, работающие с данными в выбранном направлении, а шаблон может быть спроектирован таким образом, что, когда происходит ввод данных, формулы рассчитывают правильные величины, исключая необходимость неоднократного ввода простых расчетов.
Тем не менее, все это дает в результате "плоский" отчет, что означает, что как только он создан, трудно рассматривать его в различных аспектах. Например, диаграмма отображает информацию за некоторый временной период, - скажем, за месяц. И если некто желает увидеть показатели за день (в противоположность данным за месяц), необходимо будет создать абсолютно новую диаграмму. Предстоит определить новые наборы данных, добавить в диаграмму новые метки и внести множество других простых, но трудоемких изменений. Кроме того, существует ряд областей, в которых могут быть допущены ошибки, что в целом уменьшает надежность. Когда к таблице добавляется OLAP, появляется возможность создавать единственную диаграмму, а затем подвергать ее различным манипуляциям с целью предоставления пользователю необходимой информации, не обременяя себя созданием всех возможных представлений. Интернет в роли клиента. Новым членом семейства OLAP-клиентов является Интернет. Существует масса преимуществ в формировании OLAP-отчетов через Интернет. Наиболее существенным представляется отсутствие необходимости в специализированном программном обеспечении для доступа к информации. Это экономит предприятию кучу времени и денег.
Каждый Интернет-продукт специфичен. Некоторые упрощают создание Web-страниц, но имеют меньшую гибкость. Другие позволяют создавать представления данных, а затем сохранять их как статические HTML-файлы. Все это дает возможность просматривать данные через Интернет, но не более того. Активно манипулировать данными с их помощью невозможно.
Существует и другой тип продуктов - интерактивный и динамический, превращающий такие продукты в полнофункциональные инструменты. Пользователи могут осуществлять углубление в данные, пивотинг, ограничение измерений, и др. Прежде, чем выбрать средство реализации Интернет, важно понять, какие функциональные возможности требуются от Web-решения, а затем определить, какой продукт наилучшим образом воплотит эту функциональность .
Приложения. Приложения - это тип клиента, использующий базы данных OLAP. Они идентичны инструментам запросов и генераторам отчетов, описанным выше, но, кроме того, они вносят в продукт более широкие функциональные возможности. Приложение, как правило, обладает большей мощностью, чем инструмент запроса.
Разработка. Обычно поставщики OLAP обеспечивают среду разработки для создания пользователями собственных настроенных приложений. Среда разработки в целом представляет собой графический интерфейс, поддерживающий объектно-ориентированную разработку приложений. К тому же, большинство поставщиков обеспечивают API, который может использоваться для интеграции баз данных OLAP с другими приложениями.
2.2 OLAP - клиенты
OLAP-клиенты со встроенной OLAP-машиной устанавливаются на ПК пользователей. Они не требуют сервера для вычислений, и им присуще нулевое администрирование. Такие клиенты позволяют пользователю настроиться на существующие у него базы данных; как правило, при этом создается словарь, скрывающий физическую структуру данных за ее предметным описанием, понятным специалисту. После этого OLAP-клиент выполняет произвольные запросы и результаты их отображает в OLAP-таблице. В этой таблице, в свою очередь, пользователь может манипулировать данными и получать на экране или на бумаге сотни различных отчетов. OLAP-клиенты, предназначенные для работы с РСУБД, позволяют анализировать уже имеющиеся в корпорации данные, например хранящиеся в БД OLTP . Однако вторым их назначением может быть быстрое и дешевое создание хранилищ или витрин данных - в этом случае программистам организации нужно лишь создать совокупности таблиц типа "звезда" в реляционных БД и процедуры загрузки данных. Наиболее трудоемкая часть работы - написание интерфейсов с многочисленными вариантами пользовательских запросов и отчетов - реализуется в OLAP-клиенте буквально за несколько часов. Конечному же пользователю для освоения такой программы требуется порядка 30 минут. OLAP-клиенты поставляются самими разработчиками баз данных, как многомерных, так и реляционных. Это SAS Corporate Reporter, являющийся почти эталонным по удобству и красоте продуктом, Oracle Discoverer, комплекс программ MS Pivot Services и Pivot Table и др. Многие программы, предназначенные для работы с MS OLAP Services, поставляются в рамках кампании "OLAP в массы", которую проводит корпорация Microsoft. Как правило, они являются улучшенными вариантами Pivot Table и рассчитаны на использование в MS Office или Web-браузере. Это продукты фирм Matryx, Knosys и т. д., благодаря простоте, дешевизне и эффективности приобретшие огромную популярность на Западе.
3 Классификация продуктов OLAP
3.1 Многомерный OLAP
В настоящее время на рынке присутствует большое количество продуктов, которые в той или иной степени обеспечивают функциональность OLAP. Обеспечивая многомерное концептуальное представление со стороны пользовательского интерфейса к исходной базе данных, все продукты OLAP делятся на три класса по типу исходной БД.
1. Самые первые системы оперативной аналитической обработки (например, Essbase компании Arbor Software, Oracle Express Server компании Oracle) относились к классу MOLAP, то есть могли работать только со своими собственными многомерными базами данных. Они основываются на патентованных технологиях для многомерных СУБД и являются наиболее дорогими. Эти системы обеспечивают полный цикл OLAP-обработки. Они либо включают в себя, помимо серверного компонента, собственный интегрированный клиентский интерфейс, либо используют для связи с пользователем внешние программы работы с электронными таблицами. Для обслуживания таких систем требуется специальный штат сотрудников, занимающихся установкой, сопровождением системы, формированием представлений данных для конечных пользователей.
2. Системы оперативной аналитической обработки реляционных данных (ROLAP) позволяют представлять данные, хранимые в реляционной базе, в многомерной форме, обеспечивая преобразование информации в многомерную модель через промежуточный слой метаданных. К этому классу относятся DSS Suite компании MicroStrategy, MetaCube компании Informix, DecisionSuite компании Information Advantage и другие. Программный комплекс ИнфоВизор, разработанный в России, в Ивановском государственном энергетическом университете, также является системой этого класса. ROLAP-системы хорошо приспособлены для работы с крупными хранилищами. Подобно системам MOLAP, они требуют значительных затрат на обслуживание специалистами по информационным технологиям и предусматривают многопользовательский режим работы.
3. Наконец, гибридные системы (Hybrid OLAP, HOLAP) разработаны с целью совмещения достоинств и минимизации недостатков, присущих предыдущим классам. К этому классу относится Media/MR компании Speedware. По утверждению разработчиков, он объединяет аналитическую гибкость и скорость ответа MOLAP с постоянным доступом к реальным данным, свойственным ROLAP.
Помимо перечисленных средств существует еще один класс - инструменты генерации запросов и отчетов для настольных ПК, дополненные функциями OLAP или интегрированные с внешними средствами, выполняющими такие функции. Эти хорошо развитые системы осуществляют выборку данных из исходных источников, преобразуют их и помещают в динамическую многомерную БД, функционирующую на клиентской станции конечного пользователя. Основными представителями этого класса являются BusinessObjects одноименной компании, BrioQuery компании Brio Technology и PowerPlay компании Cognos. Обзор некоторых продуктов OLAP приведен в приложении.
В специализированных СУБД, основанных на многомерном представлении данных, данные организованы не в форме реляционных таблиц, а в виде упорядоченных многомерных массивов:
1) гиперкубов (все хранимые в БД ячейки должны иметь одинаковую мерность, то есть находиться в максимально полном базисе измерений) или
2) поликубов (каждая переменная хранится с собственным набором измерений, и все связанные с этим сложности обработки перекладываются на внутренние механизмы системы).
Использование многомерных БД в системах оперативной аналитической обработки имеет следующие достоинства.
1. В случае использования многомерных СУБД поиск и выборка данных осуществляется значительно быстрее, чем при многомерном концептуальном взгляде на реляционную базу данных, так как многомерная база данных денормализована, содержит заранее агрегированные показатели и обеспечивает оптимизированный доступ к запрашиваемым ячейкам.
2. Многомерные СУБД легко справляются с задачами включения в информационную модель разнообразных встроенных функций, тогда как объективно существующие ограничения языка SQL делают выполнение этих задач на основе реляционных СУБД достаточно сложным, а иногда и невозможным.
С другой стороны, имеются существенные ограничения.
1. Многомерные СУБД не позволяют работать с большими базами данных. К тому же за счет денормализации и предварительно выполненной агрегации объем данных в многомерной базе, как правило, соответствует (по оценке Кодда) в 2.5-100 раз меньшему объему исходных детализированных данных.
2. Многомерные СУБД по сравнению с реляционными очень неэффективно используют внешнюю память. В подавляющем большинстве случаев информационный гиперкуб является сильно разреженным, а поскольку данные хранятся в упорядоченном виде, неопределенные значения удаётся удалить только за счет выбора оптимального порядка сортировки, позволяющего организовать данные в максимально большие непрерывные группы. Но даже в этом случае проблема решается только частично. Кроме того, оптимальный с точки зрения хранения разреженных данных порядок сортировки скорее всего не будет совпадать с порядком, который чаще всего используется в запросах. Поэтому в реальных системах приходится искать компромисс между быстродействием и избыточностью дискового пространства, занятого базой данных.
Следовательно, использование многомерных СУБД оправдано только при следующих условиях.
1. Объем исходных данных для анализа не слишком велик (не более нескольких гигабайт), то есть уровень агрегации данных достаточно высок.
2. Набор информационных измерений стабилен (поскольку любое изменение в их структуре почти всегда требует полной перестройки гиперкуба).
3. Время ответа системы на нерегламентированные запросы является наиболее критичным параметром.
4. Требуется широкое использование сложных встроенных функций для выполнения кроссмерных вычислений над ячейками гиперкуба, в том числе возможность написания пользовательских функций.
Непосредственное использование реляционных БД в системах оперативной аналитической обработки имеет следующие достоинства.
1. В большинстве случаев корпоративные хранилища данных реализуются средствами реляционных СУБД, и инструменты ROLAP позволяют производить анализ непосредственно над ними. При этом размер хранилища не является таким критичным параметром, как в случае MOLAP.
2. В случае переменной размерности задачи, когда изменения в структуру измерений приходится вносить достаточно часто, ROLAP системы с динамическим представлением размерности являются оптимальным решением, так как в них такие модификации не требуют физической реорганизации БД.
3. Реляционные СУБД обеспечивают значительно более высокий уровень защиты данных и хорошие возможности разграничения прав доступа.
Главный недостаток ROLAP по сравнению с многомерными СУБД - меньшая производительность. Для обеспечения производительности, сравнимой с MOLAP, реляционные системы требуют тщательной проработки схемы базы данных и настройки индексов, то есть больших усилий со стороны администраторов БД. Только при использовании звездообразных схем производительность хорошо настроенных реляционных систем может быть приближена к производительности систем на основе многомерных баз данных .
Описанию схемы звезды (star schema) и рекомендациям по ее применению полностью посвящены работы. Ее идея заключается в том, что имеются таблицы для каждого измерения, а все факты помещаются в одну таблицу, индексируемую множественным ключом, составленным из ключей отдельных измерений (Приложение А). Каждый луч схемы звезды задает, в терминологии Кодда, направление консолидации данных по соответствующему измерению.
В сложных задачах с многоуровневыми измерениями имеет смысл обратиться к расширениям схемы звезды - схеме созвездия (fact constellation schema) и схеме снежинки (snowflake schema). В этих случаях отдельные таблицы фактов создаются для возможных сочетаний уровней обобщения различных измерений (Приложение Б). Это позволяет добиться лучшей производительности, но часто приводит к избыточности данных и к значительным усложнениям в структуре базы данных, в которой оказывается огромное количество таблиц фактов.
Увеличение числа таблиц фактов в базе данных может проистекать не только из множественности уровней различных измерений, но и из того обстоятельства, что в общем случае факты имеют разные множества измерений. При абстрагировании от отдельных измерений пользователь должен получать проекцию максимально полного гиперкуба, причем далеко не всегда значения показателей в ней должны являться результатом элементарного суммирования. Таким образом, при большом числе независимых измерений необходимо поддерживать множество таблиц фактов, соответствующих каждому возможному сочетанию выбранных в запросе измерений, что также приводит к неэкономному использованию внешней памяти, увеличению времени загрузки данных в БД схемы звезды из внешних источников и сложностям администрирования.
Частично решают эту проблему расширения языка SQL (операторы GROUP BY CUBE", "GROUP BY ROLLUP" и "GROUP BY GROUPING SETS"); кроме того, предлагается механизм поиска компромисса между избыточностью и быстродействием, рекомендуя создавать таблицы фактов не для всех возможных сочетаний измерений, а только для тех, значения ячеек которых не могут быть получены с помощью последующей агрегации более полных таблиц фактов (Приложение В).
В любом случае, если многомерная модель реализуется в виде реляционной базы данных, следует создавать длинные и "узкие" таблицы фактов и сравнительно небольшие и "широкие" таблицы измерений. Таблицы фактов содержат численные значения ячеек гиперкуба, а остальные таблицы определяют содержащий их многомерный базис измерений. Часть информации можно получать с помощью динамической агрегации данных, распределенных по незвездообразным нормализованным структурам, хотя при этом следует помнить, что включающие агрегацию запросы при высоконормализованной структуре БД могут выполняться довольно медленно.
Ориентация на представление многомерной информации с помощью звездообразных реляционных моделей позволяет избавиться от проблемы оптимизации хранения разреженных матриц, остро стоящей перед многомерными СУБД (где проблема разреженности решается специальным выбором схемы). Хотя для хранения каждой ячейки используется целая запись, которая помимо самих значений включает вторичные ключи - ссылки на таблицы измерений, несуществующие значения просто не включаются в таблицу фактов.
Заключение
Рассмотрев вопросы работы и применения технологии OLAPперед компаниями возникают вопросы, ответы на которые позволят выбрать продукт наилучшим образом отвечающий потребностям пользователя.
Это следующие вопросы:
Откуда поступают данные? – Данные, подлежащие анализу, могут находиться в различных местах. Возможно, что база данных OLAP будет получать их из корпоративного Хранилища данных или из OLTP-системы. Если OLAP-продукт уже имеет возможность получить доступ к какому-то источнику данных, процессы категоризации и очистки данных сокращаются.
Какие манипуляции пользователь производит над данными? -
Как только пользователь получил доступ к базе данных и начал выполнять анализ, важно, чтобы он был в состоянии оперировать данными соответствующим образом. В зависимости от потребностей пользователя, может оказаться, что необходим мощный генератор отчетов или возможность создавать и размещать динамические web-страницы. Вместе с тем, может быть пользователю предпочтительнее иметь в своем распоряжении средство простого и быстрого создания собственных приложений.
Каков общий объем данных? - Это наиболее важный фактор при определении базы данных OLAP. Реляционные OLAP-продукты способны оперировать большими объемами данных лучше, чем многомерные. Если объем данных не требует использования реляционной базы, многомерный продукт может использоваться с не меньшим успехом.
Кем является пользователь? - При определении клиента OLAP-системы важен уровень квалификации пользователя. Некоторым пользователям удобнее интегрировать OLAP с таблицей, тогда как другие предпочтут специализированное приложение. В зависимости от квалификации пользователя решается и вопрос о проведении обучения. Крупная компания может пожелать оплатить тренинги для пользователей, компания меньшего размера может отказаться от них. Клиент должен быть таким, чтобы пользователи чувствовали себя уверенно и могли эффективно его использовать.
Сегодня большинство мировых компаний перешли к использованию OLAP как базовой технологии для предоставления информации лицам, принимающим решениям. Поэтому принципиальный вопрос, которым необходимо задаться, не состоит в том, следует ли продолжать применять электронные таблицы в качестве основной платформы для подготовки отчетности, бюджетирования и прогнозирования. Компании должны спросить себя, готовы ли они терять конкурентные преимущества, используя неточную, неактуальную и неполную информацию, прежде чем они созреют и рассмотрят альтернативные технологии.
Так же, в заключение следует отметить, что аналитические возможности технологий OLAP повышают пользу данных, хранящихся в корпоративном хранилище информации, позволяя компании более эффективно взаимодействовать со своими клиентами.
Глоссарий
| Понятие | Определение | |
| 1 | BI-инструменты | Инструменты и технологии, используемые для доступа к информации. Включают OLAP-технологии, data mining и сложный анализ; средства конечного пользователя и инструменты построения нерегламентированных запросов, инструментальные панели для мониторинга хозяйственной деятельности и генераторы корпоративной отчетности. |
| 2 | On-line Analitic Processing, OLAP (Оперативная аналитическая обработка) | Технология аналитической обработки информации в режиме реального времени, включающая составление и динамическую публикацию отчетов и документов. |
| 3 | Slice and Dice (Продольные и поперечные срезы, дословно - "нарезка на ломтики и кубики") | Термин, использующийся для описания функции сложного анализа данных, обеспечиваемой средствами OLAP. Выборка данных из многомерного куба с заданными значениями и заданным взаимным расположением измерений. |
| 4 | Вращение (пивотинг) данных (Data Pivot) | Процесс вращения таблицы с данными, т. е. преобразования столбцов в строки и наоборот. |
| 5 | Вычисленный элемент (Calculated member) | Элемент измерения, чья величина определяется величинами других элементов (например, математическими или логическими приложениями). Вычисленный элемент может представлять собой часть OLAP сервера или быть описан пользователем в течение интерактивной сессии. Вычисленный элемент - это любой элемент, который не вводится, а вычисляется. |
| 6 | Глобальные бизнес-модели (Global Business Models) | Тип Хранилища данных, обеспечивающий доступ к информации, которая распределена по различным системам предприятия и находится под контролем различных подразделений или отделов с разными базами данных и моделями данных. Такой тип Хранилища данных труден для построения из-за необходимости объединения усилий пользователей различных подразделений для разработки общей модели данных для Хранилища. |
| 7 | Добыча данных (Data Mining) | Технические приемы, использующие программные инструменты, предназначенные для такого пользователя, который, как правило, не может заранее сказать, что конкретно он ищет, а может указать лишь определенные образцы и направления поиска. |
| 8 | Клиент/Сервер (Client/Server) | Технологический подход, заключающийся в разделении процесса на отдельные функции. Сервер выполняет несколько функций - управление коммуникациями, обеспечение обслуживания базы данных и др. Клиент выполняет индивидуальные пользовательские функции - обеспечение соответствующих интерфейсов, выполнение межэкранной навигации, предоставление функций помощи (help) и др. |
| 9 | Многомернаябазаданных, СУMБД(Multi-dimensional Database, MDBS and MDBMS) | Мощная база данных, позволяющая пользователям анализировать большие объемы данных. База данных со специальной организацией хранения - кубами, обеспечивающая высокую скорость работы с данными, хранящимися как совокупность фактов, измерений и заранее вычисленных агрегатов. |
| 10 | Углубление в данные (Drill Down) | Метод изучения детальных данных, используемый при анализе суммарного уровня данных. Уровни "углубления" зависят от степени детализации данных в [ранилище. |
| 11 | Центральное Хранилище (Central Warehouse) | 1. База данных, содержащая данные, собираемые из операционных систем организации. Имеет структуру, удобную для анализа данных. Предназначена для поддержки принятия решений и создания единого информационного пространства корпорации. 2. Способ автоматизации, охватывающий все информационные системы, управляемые из одного места. |
1 Голицина О.Л., Максимов Н.В., Попов И.И. Базы данных: Учебное пособие. – М.: ФОРУМ: ИНФРА-М, 2003. – 352 с.
2 Дейт К. Введение в системы баз данных. – М.: Hаука, 2005 г. – 246 с.
3 Елманова Н.В., Федоров А.А. Введение в OLAP-технологии Microsoft. – М.:Диалог-МИФИ, 2004. – 312 с.
4 Карпова Т.С. Базы данных: модели, разработка, реализация. – СПб.: Питер, 2006. – 304 с.
5 Коровкин С. Д., Левенец И. А., Ратманова И. Д., Старых В. А., Щавелёв Л. В. Решение проблемы комплексного оперативного анализа информации хранилищ данных // СУБД. - 2005. - № 5-6. - 47-51 с.
6 Кречетов Н., Иванов П. Продукты для интеллектуального анализа данных ComputerWeek-Москва. - 2003. - № 14-15. - 32-39 с.
7 Пржиялковский В. В. Сложный анализ данных большого объема: новые перспективы компьютеризации // СУБД. - 2006. - № 4. - 71-83 с.
8 Сахаров А. А. Концепция построения и реализации информационных систем, ориентированных на анализ данных // СУБД. - 2004. - № 4. - 55-70 с.
9 Ульман Дж. Основы систем баз данных. – М.: Финансы и статистика, 2003. – 312 c.
10 Хаббард Дж. Автоматизированное проектирование баз данных. – М.: Мир, 2007. – 294 с.
Коровкин С. Д., Левенец И. А., Ратманова И. Д., Старых В. А., Щавелёв Л. В. Решение проблемы комплексного оперативного анализа информации хранилищ данных // СУБД. - 2005. - № 5-6. - 47-51 с.
Ульман Дж. Основы систем баз данных. – М.: Финансы и статистика, 2003. – 312 c.
Барсегян А.А., Куприянов М.С. Технологии анализа данных: DataMining, VisualMining, TextMining, Olap. – СПб.: BHV-Петербург, 2007. – 532 с.
Елманова Н.В., Федоров А.А. Введение в OLAP-технологии Microsoft. – М.:Диалог-МИФИ, 2004. – 312 с.
Дейт К. Введение в системы баз данных. – М.: Hаука, 2005 г. – 246 с.
Голицина О.Л., Максимов Н.В., Попов И.И. Базы данных: Учебное пособие. – М.: ФОРУМ: ИНФРА-М, 2003. – 352с.
Сахаров А. А. Концепция построения и реализации информационных систем, ориентированных на анализ данных // СУБД. - 2004. - № 4. - 55-70 с.
Пржиялковский В. В. Сложный анализ данных большого объема: новые перспективы компьютеризации // СУБД. - 2006. - № 4. - 71-83 с.
Концепция технологии OLAP была сформулирована Эдгаром Коддом в 1993 г.
Эта технология основана на построении многомерных наборов данных - так называемых OLAP-кубов (не обязательно трехмерных, как можно было бы заключить из определения). Целью использования технологий OLAP является анализ данных и представление этого анализа в виде, удобном для восприятия управляющим персоналом и принятия на их основе решений.
Основные требования, предъявляемые к приложениям для многомерного анализа:
- - предоставление пользователю результатов анализа за приемлемое время (не более 5 с.);
- - многопользовательский доступ к данным;
- - многомерное представление данных;
- - возможность обращаться к любой информации независимо от места ее хранения и объема.
Инструменты OLAP-систем обеспечивают возможность сортировки и выборки данных по заданным условиям. Могут задаваться различные качественные и количественные условия.
Основной моделью данных, использованной в многочисленных инструментальных средствах создания и поддержки баз данных - СУБД, является реляционная модель. Данные в ней представлены в виде множества связанных ключевыми полями двумерных таблиц-отношений. Для устранения дублирования, противоречивости, уменьшения трудозатрат на ведение баз данных применяется формальный аппарат нормализации таблиц-сущностей. Однако применение его связано с дополнительными затратами времени на формирование ответов на запросы к базам данных, хотя и экономятся ресурсы памяти.
Многомерная модель данных представляет исследуемый объект в виде многомерного куба, чаще используют трехмерную модель. По осям или граням куба откладываются измерения или реквизиты-признаки. Реквизиты-основания являются наполнением ячеек куба. Многомерный куб может быть представлен комбинацией трехмерных кубов с целью облегчения восприятия и представления при формировании отчетных и аналитических документов и мультимедийных презентаций по материалам аналитических работ в системе поддержки принятия решений.
В рамках OLAP-технологий на основе того, что многомерное представление данных может быть организовано как средствами реляционных СУБД, так многомерных специализированных средств, различают три типа многомерных OLAP-систем:
- - многомерный (Multidimensional) OLAP-MOLAP;
- - реляционный (Relation) OLAP-ROLAP;
- - смешанный или гибридный (Hibrid) OLAP-HOLAP.
В многомерных СУБД данные организованы не в виде реляционных таблиц, а в виде упорядоченных многомерных массивов в виде гиперкубов, когда все хранимые данные должны иметь одинаковую размерность, что означает необходимость образовывать максимально полный базис измерений. Данные могут быть организованы в виде поликубов, в этом варианте значения каждого показателя хранятся с собственным набором измерений, обработка данных производится собственным инструментом системы. Структура хранилища в этом случае упрощается, т.к. отпадает необходимость в зоне хранения данных в многомерном или объектно-ориентированном виде. Снижаются огромные трудозатраты на создание моделей и систем преобразования данных из реляционной модели в объектную.
Достоинствами MOLAP являются:
- - более быстрое, чем при ROLAP получение ответов на запросы - затрачиваемое время на один-два порядка меньше;
- - из-за ограничений SQL затрудняется реализация многих встроенных функций.
К ограничениям MOLAP относятся:
- - сравнительно небольшие размеры баз данных;
- - за счет денормализации и предварительной агрегации многомерные массивы используют в 2,5-100 раз больше памяти, чем исходные данные (расход памяти при увеличении числа измерений растет по экспоненциальному закону);
- - отсутствуют стандарты на интерфейс и средства манипулирования данными;
- - имеются ограничения при загрузке данных.
Трудозатраты на создание многомерных данных резко увеличиваются, т.к. практически отсутствуют в этой ситуации специализированные средства объективизации реляционной модели данных, содержащихся в информационном хранилище. Время отклика на запросы часто не может уложиться в рамки требований к OLAP-системам.
Достоинствами ROLAP-систем являются:
- - возможность оперативного анализа непосредственно содержащихся в хранилище данных, т.к. большинство исходных баз данных - реляционного типа;
- - при переменной размерности задачи выигрывают RO- LAP, т.к. не требуется физическая реорганизация базы данных;
- - ROLAP-системы могут использовать менее мощные клиентские станции и серверы, причем на серверы ложится основная нагрузка по обработке сложных SQL-запросов;
- - уровень защиты информации и разграничения прав доступа в реляционных СУБД несравненно выше чем в многомерных.
Недостатком ROLAP-систем является меньшая производительность, необходимость тщательной проработки схем базы данных, специальная настройка индексов, анализ статистики запросов и учет выводов анализа при доработках схем баз данных, что приводит к значительным дополнительным трудозатратам.
Выполнение же этих условий позволяет при использовании ROLAP-систем добиться схожих с MOLAP-системами показателей в отношении времени доступа, а также превзойти в экономии памяти.
Гибридные OLAP-системы представляют собой сочетание инструментов, реализующих реляционную и многомерную модель данных. Это позволяет резко снизить затраты ресурсов на создание и поддержание такой модели, время отклика на запросы.
При таком подходе используются достоинства первых двух подходов и компенсируются их недостатки. В наиболее развитых программных продуктах такого назначения реализован именно этот принцип.
Использование гибридной архитектуры в OLAP-системах - это наиболее приемлемый путь решения проблем, связанных с применением программных инструментальных средств в многомерном анализе.
Режим выявления закономерностей основан на интеллектуальной обработке данных. Главной задачей здесь является выявление закономерностей в исследуемых процессах, взаимосвязей и взаимовлияния различных факторов, поиск крупных «непривычных» отклонений, прогноз хода различных существенных процессов. Эта область относится к интеллектуальному анализу (Data mining).