Выполнение сложных SQL-запросов. Оператор для наборов данных EXCEPT общие правила Sql except примеры
Нюансы
Меня часто спрашивают, а для кого эта статья? Но, поверьте, не всегда легко дать ответить: с одной стороны, есть ниндзя разработчики, которых сложно чем то удивить, а с другой - молодые падаваны. Но одно точно могу сказать - для читателя, которого интересует SQL, который способен дополнять свою богатую картину мелкими, но очень интересными деталями. В данной статье не будет километровых страниц sql-запроса, максимум 1, 2 строчки и только то, что встречается на мой взгляд редко. Но так как я хочу быть до конца откровенным, если Вы с sql на ты, статья покажется скучноватой. Все примеры в статье, за исключением первого и четвертого можно отнести к стандарту SQL-92.Данные
Для того, чтобы упростить нам жизнь, я накидал простую табличку с данными, на которой будут опробованы те или иные моменты и для краткости, я буду приводить результат эксперимента над ними. Все запросы я проверяю на PostgreSql.Скрипты и таблица с данными
CREATE TABLE goods(id bigint NOT NULL,
name character varying(127) NOT NULL,
description character varying(255) NOT NULL,
price numeric(16,2) NOT NULL,
articul character varying(20) NOT NULL,
act_time timestamp NOT NULL,
availability boolean NOT NULL,
CONSTRAINT pk_goods PRIMARY KEY (id));
INSERT INTO goods (id, name, description, price, articul, act_time, availability) VALUES (1, "Тапочки", "Мягкие", 100.00, "TR-75", {ts "2017-01-01 01:01:01.01"}, TRUE);
INSERT INTO goods (id, name, description, price, articul, act_time, availability) VALUES (2, "Подушка", "Белая", 200.00, "PR-75", {ts "2017-01-02 02:02:02.02"}, TRUE);
INSERT INTO goods (id, name, description, price, articul, act_time, availability) VALUES (3, "Одеяло", "Пуховое", 300.00, "ZR-75", {ts "2017-01-03 03:03:03.03"}, TRUE);
INSERT INTO goods (id, name, description, price, articul, act_time, availability) VALUES (4, "Наволочка", "Серая", 400.00, "AR-75", {ts "2017-01-04 04:04:04.04"}, FALSE);
INSERT INTO goods (id, name, description, price, articul, act_time, availability) VALUES (5, "Простынка", "Шелковая", 500.00, "BR-75", {ts "2017-01-05 05:05:05.05"}, FALSE);
Запросы
1. Двойные кавычки
И первое что у меня есть - это простой вопрос: Смогли бы Вы привести пример sql-запроса c использованием двойных кавычек? Да, не с одинарными, двойными?Пример с двойными кавычками
SELECT name "Имя товара" FROM goods
Я был очень удивлен, когда увидел это в первый раз. Если попробовать изменить двойные кавычки на одинарные, результат будет совершенно иной !
Может показаться, что это не очень полезный пример для реальной разработки. Для меня это не так. Теперь я его активно использую во всех своих sql-заготовках. Суть проста, когда возвращаешься через пол года к sql-запросу из 40 колонок, ой как спасает "нашенское" их название. Не смотря, что я не указал про SQL-92, в последней редакции упоминание про двойные кавычки имеются.
2. Псевдо таблица. SQL-92
Немного не точно, с точки зрения терминологии, но суть проста - таблица получающаяся в результате подзапроса в секции FROM. Пожалуй самый известный факт в этой статьеПсевдо таблица
SELECT mock.nickname "Прозвище", (CASE WHEN mock.huff THEN "Да" ELSE "Нет" END) "Обижается?" FROM (SELECT name AS nickname, availability AS huff FROM goods) mock
В нашем примере mock - это псевдо таблица (иногда называют виртуальной таблицей). Естественно, предназначены они вовсе не для того, чтобы переврать истинный смысл. Пример такой.
3. Конструктор блока данных. SQL-92
Звучит страшно, просто из-за того, что я не нашел хорошего перевода или интерпретации. И как всегда на примере легче объяснить:Пример конструктора блока данных
SELECT name "Имя товара", price "Цена" FROM (VALUES ("Тапочки", 100.00), ("Подушка", 200.00)) AS goods(name, price)
| Имя товара | Цена |
| Тапочки | 100.00 |
| Подушка | 200.00 |
В секции FROM используется ключевой слово VALUES , за которым в скобках данные, строка за строкой. Суть в том, что мы вообще не выбираем данные из какой-то таблицы, а просто создаем их налету, "называем" таблицей, именуем колонки и далее используем по своему усмотрению. Эта штука оказалось крайне полезной при тестировании разных кейсов sql-запроса, когда данных для некоторых таблиц нет (в Вашей локальной БД), а писать insert лень или иногда очень сложно, ввиду связанности таблиц и ограничений.
4. Время, Дата и Время-и-Дата
Наверное каждый сталкивался в запросах, с необходимостью указания времени, даты или даты-и-времени. Во многих СУБД поддерживаются литералы t, d и ts соответственно для работы с этими типами. Но проще объяснить на примере:Для литералов d и t все аналогично.Прошу прощение у читателя, что ввел в заблуждение, но все что сказано в пункте 4 не относится к языку SQL, а относится к возможностям предобработки запросов в JDBC.
5. Отрицание. SQL-92
Все мы знаем про оператор NOT , но очень часто забывают, что его можно применять как к группе предикатов так и к одиночной колонке:6. Сравнение блоков данных. SQL-92
В очередной раз прошу прощение за терминологию. Это один из любимых моих примеровПример сравнения блоков данных
SELECT * FROM goods WHERE (name, price, availability) = ("Наволочка", 400.00, FALSE) -- или его аналог SELECT * FROM goods WHERE name = "Наволочка" AND price = 400.00 AND availability = FALSE
Как видно из примера, сравнение блоков данных аналогично сравнению поэлементно значение_1 _block_1 = значение_1 _block_2, значение_2 _block_1 = значение_2 _block_2, значение_3 _block_1 = значение_3 _block_2 с использованием AND между ними.
7. Операторы сравнения с модификаторами ANY, SOME или ALL. SQL-92
Вот здесь требуется пояснение. Но как всегда, сначала примерЧто означает ALL в данном случае? А означает он то, что условию выборки удовлетворяют только те строки, идентификаторы которых (в нашем случае это 4 и 5), больше любого из найденных значений в подзапросе (1, 2 и 3). 4 больше чем 1 и чем 2 и чем 3. 5 аналогично. Что будет, если мы заменим ALL на ANY ?Что означает ANY в данном случае? А означает он то, что условию выборки удовлетворяют только те строки, идентификаторы которых (в нашем случае это 2, 3, 4 и 5), больше хотя бы одного из найденных значений в подзапросе (1, 2 и 3). Для себя я ассоциировал ALL с AND , а ANY с OR . SOME и ANY аналоги между собой.
8. Операторы работы с запросами/под запросами. SQL-92
Достаточно известно, что можно объединить 2 запроса между собой с помощью операторов UNION или UNION ALL . Этим пользуются часто. Но существуют еще 2 оператора EXCEPT и INTERSECT .Пример с EXCEPT
Собственно из первого множества значений исключаются данные второго множества.
Собственно происходит пересечение первого множества значений и второго множества.
На этом все, спасибо за Ваше внимание.
Редакция
N1. Спасибо streetflush за конструктивную критику. Внес статью информацию о том, что является стандартом языка, а что нет.N2. Исправлен пункт 4, с пояснение о том, что ts/d/t не являюься частью языка SQL. Спасибо за внимательность Melkij.
Оператор INTERSECT извлекает идентичные строки из результирующих наборов одного или нескольких запросов. В некотором отношении оператор INTERSECT очень напоминает INNER JOIN.
INTERSECT относится к классу операторов для работы с наборами данных (set operator). К другим таким операторам относятся EXCEPT и UNION. Все операторы для наборов данных используются для одновременного манипулирования результирующими наборами двух и более запросов, отсюда и их название.
Синтаксис SQL2003
Технических ограничений на количество запросов в операторе INTERSECT не существует. Общий синтаксис следующий.
INTERSECT
] INTERSECT
Ключевые слова
Включаются дублирующиеся строки из всех результирующих наборов.
DISTINCT
Дублирующиеся строки удаляются из всех результирующих наборов перед сравнением, проводимым оператором INTERSECT. Столбцы с пустыми (NULL) значениями считаются дублирующимися. Если не указано ни ключевое слово ALL, ни DISTINCT, то по умолчанию подразумевается DISTINCT.
CORRESPONDING
Указывается, что возвращаться будут только те столбцы, которые имеют в обоих запросах одно имя, даже если в обоих запросах используется обобщающий символ (*).
Указывается, что возвращаться будут только названные столбцы, даже если запросы обнаруживают другие столбцы с соответствующими именами. Это предложение должно использоваться вместе с ключевым словом CORRESPONDING.
Общие правила
Есть только одно важное правило, которое необходимо помнить при работе с оператором INTERSECT.
Порядок и количество столбцов во всех запросах должно быть одинаково. Типы данных соответствующих столбцов также должны быть совместимы.
Например, типы CHAR и VARCHAR совместимы. По умолчанию для результирующего набора в каждом столбце будет использоваться размер, соответствующий самому большому типу в каждом конкретном положении.
Ни одна из платформ не поддерживает предложение CORRESPONDING .
Согласно стандарту ANSI оператор INTERSECT имеет более высокий приоритет по сравнению с другими операторами для работы с наборами, хотя на разных платформах приоритет таких операторов обрабатывается по-разному. Вы можете явным образом управлять приоритетом операторов, используя скобки. В противном случае СУБД может выполнять их в порядке слева направо или от первого к последнему.
Согласно стандарту ANSI в запросе можно использовать только одно предложение ORDER BY. Вставляйте его в самый конец последней инструкции SELECT. Чтобы избежать двусмысленности в указании столбцов и таблиц, обязательно присваивайте один и тот же псевдоним всем соответствующим друг другу столбцам таблиц. Например:
На платформах, которые не поддерживают оператор INTERSECT, вы можете заменить его подзапросом FULL JOIN.
SELECT a.au_lname AS "lastname", a.au_fname AS "firstname" FROM authors AS a INTERSECT SELECT e.emp_lname AS "lastname", e.emp_fname AS "firstname" FROM employees AS e ORDER BY lastname, firstname;
Поскольку типы данных столбцов в разных запросах оператора INTERSECT могут оказываться совместимыми, на разных платформах СУРБД могут встречаться разные варианты работы со столбцами разной длины. Например, если столбец aujname из первого запроса в предыдущем примере значительно длиннее, чем столбец empjname из второго запроса, то разные платформы могут применять разные правила определения длины конечного результата. Но, вообще говоря, платформы будут выбирать для результата более длинный (и менее ограниченный) размер.
Каждая СУРБД может применять свои собственные правила использования имени столбца в том случае, если имена в списках столбцов различаются. Обычно используются имена столбцов первого запроса.
DB2
Платформа DB2 поддерживает ключевые слова INTERSECT и INTERSECT ALL стандарта ANSI плюс дополнительное предложение VALUES.
{инструкция._SELECT_7 | VALUES (выраж7 [, …])} INTERSECT
] {инструкция_SCJ_2 | VALUES {выраж2 [, …])} INTERSECT
Хотя инструкция INTERSECT DISTINCT не поддерживается, функциональным эквивалентом является INTERSECT. Предложение CORRESPONDING не поддерживается.
Кроме того, типы данных LONG VARCHAR, LONG VARGRAPHIC, BLOB, CLOB, DBCLOB, DATALINK и структурные типы не применяются в предложении INTERSECT, но их можно использовать в предложении INTERSECT ALL.
Если в результирующем наборе данных есть столбец, имеющий одно и то же имя во всех инструкциях SELECT, то это имя используется в качестве окончательного имени для столбца, возвращаемого инструкцией. Если же в запросах для столбца используются разные имена, то платформа DB2 сгенерирует для результирующего столбца новое имя. После этого становится непригодным для использования в предложениях ORDER BY и FOR UPDATE.
Если в одном запросе используется несколько операторов для работы с наборами данных, то первым выполняется тот, который заключен в скобки. После этого порядок выполнения будет слева направо. Тем не менее все операторы INTERSECT выполняются до операторов UNION и EXCEPT, например:
SELECT empno FROM employee WHERE workdept LIKE "E%" INTERSECT (SELECT empno FROM emp_act WHERE projno IN ("IF1000", "IF2000", "AD3110") UNION VALUES ("AA0001"), ("AB0002"), ("AC0003"))
В приведенном выше примере из таблицы employee извлекаются идентификаторы (ID) всех служащих, работающих в департаменте, название которого начинается с «Е». Однако идентификаторы извлекаются только в том случае, если они также существуют в таблице учетных записей служащих с именем emp_act и участвуют в проектах IF1000, IF200" и AD3110.
Существует только одно важное правило использования инструкции EXCEPT, которое нужно запомнить.
Порядок, количество и типы данных столбцов должны быть однотипны во всех запросах.
Согласно стандарту ANSI операторы работы с наборами UNION и EXCEPT имеют одинаковый приоритет, однако оператор INTERSECT выполняется перед другими операторами для наборов. Мы рекомендуем явным образом управлять приоритетом операторов, используя скобки. Это вообще является очень хорошей практикой.
Согласно стандарту ANSI в запросе можно использовать только одно предложение ORDER BY. Вставляйте его в самый конец последней инструкции SELECT. Чтобы избежать двусмысленности в указании столбцов и таблиц, обязательно присваивайте один и тот же псевдоним всем соответствующим друг другу столбцам таблиц. Например:
SELECT au_lname AS "lastname", au_fname AS "firstname" FROM authors EXCEPT SELECT emp_lname AS "lastname", emp_fname AS "firstname" FROM employees ORDER BY lastname, firstname;
Кроме того, поскольку в каждом списке столбцов столбцы могут указываться с соответственно совместимыми типами данных, на разных платформах СУРБД могут встречаться разные варианты работы со столбцами разной длины. Например, если столбец au_lname из первого запроса в предыдущем примере значительно длиннее, чем столбец emp_lname из второго запроса, то разные платформы могут применять разные правила определения длины конечного результата. Но, вообще говоря, платформы будут выбирать для результата более длинный (и менее ограниченный) размер.
Каждая СУРБД может применять свои собственные правила использования имени столбца в том случае, если имена в списках столбцов различаются. В общем случае используются имена столбцов первого запроса.
Типы данных не обязательно должны быть идентичны, но они должны быть совместимы. Например, типы CHAR и VARCHAR совместимы. По умолчанию для результирующего набора в каждом столбце будет использоваться размер, соответствующий самому большому типу в каждом конкретном положении. Например, запрос, извлекающий данные из столбцов, содержащих значения типа VARCHAR(IO) и VARCHAR(15), будет использовать тип и размер VARCHAR(15).
Ни одна из платформ не поддерживает предложение CORRESPONDING )} EXCEPT
{SELECT statemenr.2 | VALUES (expressionl, expression2 [, …])} EXCEPT
Позволяет указывать один или несколько задаваемых вручную столбцов, которые включаются в окончательный результирующий набор. (Это называется конструктором строк.) В предложении VALUES должно быть указано ровно столько столбцов, сколько их указывается в запросах оператора EXCEPT. Хотя инструкция EXCEPT DISTINCT не поддерживается, функциональным эквивалентом является EXCEPT. Предложение CORRESPONDING не поддерживается. Кроме того, типы данных LONG VARCHAR, LONG VARGRAPHIC, BLOB, CLOB, DBCLOB, DATALINK и структурные типы не применяются в предложении EXCEPT, но их можно использовать в предложении EXCEPT ALL.
Если в результирующем наборе данных есть столбец, имеющий одно и то же имя во всех инструкциях SELECT, то это имя используется в качестве окончательного имени для столбца, возвращаемого инструкцией. Если же данный столбец по-разному называется в разных инструкциях SELECT, то вы должны переименовать столбец во всех запросах, используя во всех них одно и то же предложение AS псевдоним.
Если в одном запросе используется несколько операторов для работы с наборами данных, то первым выполняется тот, который заключен в скобки. После этого порядок выполнения будет слева направо. Тем не менее все операторы INTERSECT выполняются до операторов UNION и EXCEPT. Например:
SELECT empno FROM employee WHERE workdept LIKE "E%" EXCEPT SELECT empno FROM emp_act WHERE projno IN (TF1000", TF2000", -AD3110")) UNION VALUES ("AA0001"), ("AB0002"), ("AC0003");
В приведенном выше примере из таблицы employee извлекаются идентификаторы (ID) всех служащих, работающих в департаменте, название которого начинается с «Е», затем из таблицы учетных записей служащих (emp_act) исключаются ID тех, кто занят в проектах IF1000, IF200" и AD3110. И наконец, добавляется три дополнительных ID - АА0001, AB0002 и AC0003 при помощи оператора работы с наборами UNION.
MySQL
В MySQL оператор EXCEPT не поддерживается. В качестве альтернативы вы можете использовать операции NOT IN или NOT EXISTS.
SQL предоставляет два способа объединения таблиц:- указывая соединяемые таблицы (в том числе подзапросы) во фразе FROM оператора SELECT . Сначала выполняется соединение таблиц, а уже потом к полученному множеству применяются указанные фразой WHERE условия, определяемое фразой GROUP BY агрегирование, упорядочивание данных и т.п.;
- определяя объединение результирующих наборов, полученных при обработке оператора SELECT . В этом случае два оператора SELECT соединяются фразой UNION , INTERSECT , EXCEPT или CORRESPONDING .
UNION-объединение
Фраза UNION объединяет результаты двух запросов по следующим правилам:
Стандарт не накладывает никаких ограничений на упорядочивание строк в результирующем наборе. Так, некоторые СУБД сначала выводят результат первого запроса, а затем - результат второго запроса. СУБД Oracle автоматически сортирует записи по первому указанному столбцу даже в том случае, если для него не создан индекс.
Для того чтобы явно указать требуемый порядок сортировки, следует использовать фразу ORDER BY . При этом можно использовать как имя столбца, так и его номер (рис. 4.3).

Рис. 4.3.
Фраза UNION ALL выполняет объединение двух подзапросов аналогично фразе UNION со следующими исключениями:
- совпадающие строки не удаляются из формируемого результирующего набора;
- объединяемые запросы выводятся в результирующем наборе последовательно без упорядочивания.
При объединении более двух запросов для изменения порядка выполнения операции объединения можно использовать скобки (рис. 4.4).

Рис. 4.4.
INTERSECT-объединение
Фраза INTERSECT позволяет выбрать только те строки, которые присутствуют в каждом объединяемом результирующем наборе. На рис. 4.5 приведен пример объединения запросов как пересекающихся множеств.

Рис. 4.5.
EXCEPT-объединение
Фраза EXCEPT позволяет выбрать только те строки, которые присутствуют в первом объединяемом результирующем наборе, но отсутствуют во втором результирующем наборе.
Фразы INTERSECT и EXCEPT должны поддерживаться только при полном уровне соответствия стандарту SQL-92. Так, некоторые СУБД вместо фразы
На уроке будет рассмотрена тема использования операций объединения, пересечения и разности запросов. Разобраны примеры того, как используется SQL запрос Union, Exists, а также использование ключевых слов SOME, ANY и All. Рассмотрены строковые функции
Над множеством можно выполнять операции объединения, разности и декартова произведения. Те же операции можно использовать и в sql запросах (выполнять операции с запросами).
Для объединения нескольких запросов используется служебное слово UNION .
Синтаксис:
< запрос 1 > UNION [ ALL ] < запрос 2 > <запрос 1> UNION <запрос 2>
SQL запрос Union служит для объединения выходных строк каждого запроса в один результирующий набор.
Если используется параметр ALL , то сохраняются все дубликаты выходных строк. Если параметр отсутствует, то в результирующем наборе остаются только уникальные строки.
Объединять вместе можно любое число запросов.
Использование оператора UNION требует выполнения нескольких условий:
- количество выходных столбцов каждого из запросов должно быть одинаковым;
- выходные столбцы каждого из запросов должны быть сравнимы между собой по типам данных (в порядке их очередности);
- в итоговом наборе используются имена столбцов, заданные в первом запросе;
- ORDER BY может быть использовано только в конце составного запроса, так как оно применяетя к результату объединения.
Пример: Вывести цены на компьютеры и ноутбуки, а также их номера (т.е. произвести выгрузку из двух разных таблиц в одном запросе)
✍ Решение:
| 1 2 3 4 5 6 | SELECT `Номер` , `Цена` FROM pc UNION SELECT `Номер` , `Цена` FROM notebook ORDER BY `Цена` |
SELECT `Номер` , `Цена` FROM pc UNION SELECT `Номер` , `Цена` FROM notebook ORDER BY `Цена`
Результат:
Рассмотрим более сложный пример с объединением inner join:
Пример: Найти тип продукции, номер и цену компьютеров и ноутбуков
✍ Решение:
| 1 2 3 4 5 6 7 8 | SELECT product. `Тип` , pc. `Номер` , `Цена` FROM pc INNER JOIN product ON pc. `Номер` = product. `Номер` UNION SELECT product. `Тип` , notebook. `Номер` , `Цена` FROM notebook INNER JOIN product ON notebook. `Номер` = product. `Номер` ORDER BY `Цена` |
SELECT product.`Тип` , pc.`Номер` , `Цена` FROM pc INNER JOIN product ON pc.`Номер` = product.`Номер` UNION SELECT product.`Тип` , notebook.`Номер` , `Цена` FROM notebook INNER JOIN product ON notebook.`Номер` = product.`Номер` ORDER BY `Цена`
Результат:
SQL Union 1. Найти производителя, номер и цену всех ноутбуков и принтеров
SQL Union 2. Найти номера и цены всех продуктов, выпущенных производителем Россия
SQL Предикат существования EXISTS
В языке SQL есть средства для выполнения операций пересечения и разности запросов — предложение INTERSECT (пересечение) и предложение EXCEPT (разность). Эти предложения работают подобно тому, как работает UNION: в результирующий набор попадают только те строки, которые присутствуют в обоих запросах — INTERSECT , или только те строки первого запроса, которые отсутствуют во втором — EXCEPT . Но беда в том, что многие СУБД не поддерживают эти предложения. Но выход есть — использование предиката EXISTS .
Предикат EXISTS принимает значение TRUE (истина), если подзапрос возвращает хоть какое-нибудь количество строк, иначе EXISTS принимает значение FALSE. Существует также предикат NOT EXISTS, который действует противоположным образом.
Обычно EXISTS используется в зависимых подзапросах (например, IN).
EXISTS(табличный подзапрос)
Пример: Найти тех производителей компьютеров, которые производят также и ноутбуки
✍ Решение:
SELECT DISTINCT Производитель FROM product AS pc_product WHERE Тип = "Компьютер" AND EXISTS (SELECT Производитель FROM product WHERE Тип = "Ноутбук" AND Производитель = pc_product.Производитель)
Результат:
Найти тех производителей компьютеров, которые не производят принтеров
Ключевые слова SQL SOME | ANY и ALL
Ключевые слова SOME и ANY являются синонимами, поэтому в запросе можно использовать любое из них. Результатом такого запроса будет являться один столбец величин.
Синтаксис:
< выражение>< оператор сравнения> SOME | ANY (< подзапрос> ) <выражение><оператор сравнения>SOME | ANY (<подзапрос>)
Если для какого-нибудь значения X , получаемого из подзапроса, результат операции « » возвращает TRUE , то предикат ANY также равняется TRUE .
Пример: Найти поставщиков компьютеров, у которых номера отсутствуют в продаже (т.е. отсутствуют в таблице pc)
✍ Решение:
Исходные данные таблиц:
Результат:
В примере предикат Номер = ANY(SELECT Номер FROM pc) вернет в том случае значение TRUE, когда Номер из основного запроса найдется в списке Номеров таблицы pc (возвращаемом подзапросом). Кроме того, используется NOT . Результирующий набор будет состоять из одного столбца — Производитель. Чтобы один производитель не выводился несколько раз, введено служебное слово DISTINCT .
Теперь рассмотрим использование ключевого слова ALL:
Пример: Найти номера и цены ноутбуков, стоимость которых превышает стоимость любого компьютера
✍ Решение:
Важно: Стоит заметить, что в общем случае запрос с ANY возвращает множество значений. Поэтому использование подзапроса в предложении WHERE без операторов EXISTS , IN , ALL и ANY , которые дают булево значение (логическое), может привести к ошибке времени выполнения запроса
Пример: Найти номера и цены компьютеров, стоимость которых превышает минимальную стоимость ноутбуков
✍ Решение:
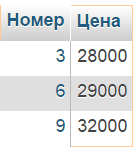
Этот запрос корректен по той причине, что скалярное выражение Цена сравнивается с подзапросом, который возвращает единственное значение
Функции работы со строками в SQL
Функция LEFT вырезает слева из строки заданное вторым аргументом число символов:
LEFT (<строка>,<число>)
Функция RIGHT возвращает заданное число символов справа из строкового выражения:
RIGHT(<строка>,<число>)
Пример: Вывести первые буквы из названий всех производителей
✍ Решение:
SELECT DISTINCT LEFT(`Производитель` , 1) FROM `product`
Результат:
Пример: Вывести названия производителей, которые начинаются и заканчиваются на одну и ту же букву
✍ Решение:
Функция SQL Replace
Синтаксис:
SELECT `name` , REPLACE(`name` , "а", "аа") FROM `teachers`